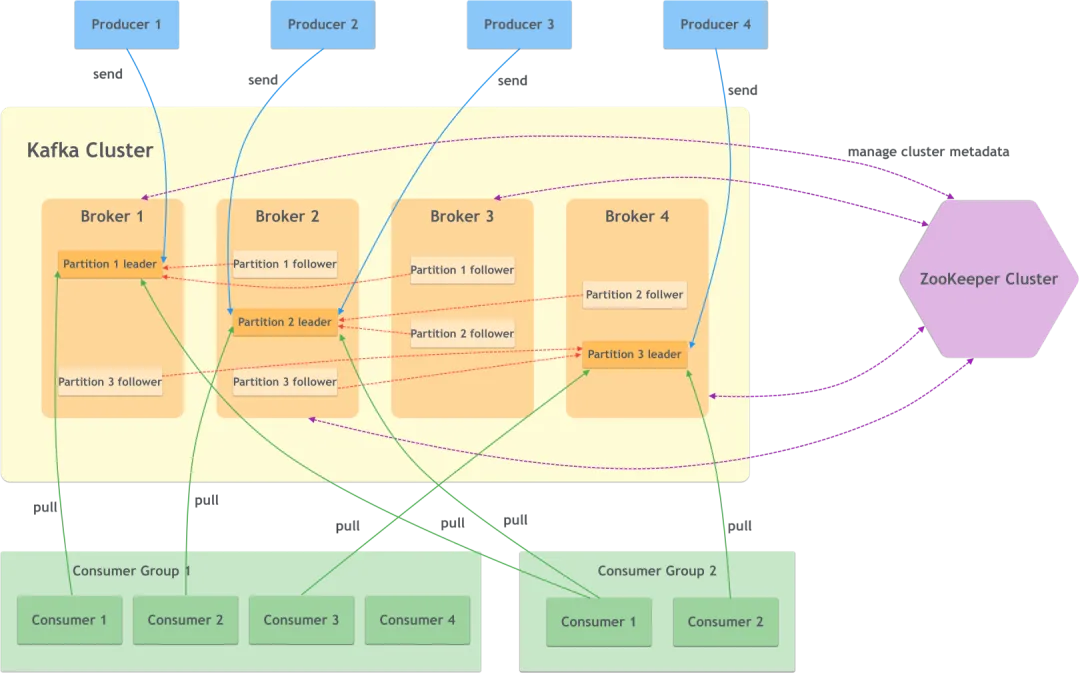
Structure
- Broker
- Producer
- Consumer
- Consumer Group
- Zookeeper
- Topic
- Partition
- Replica
- Leader and Follower
- Offset
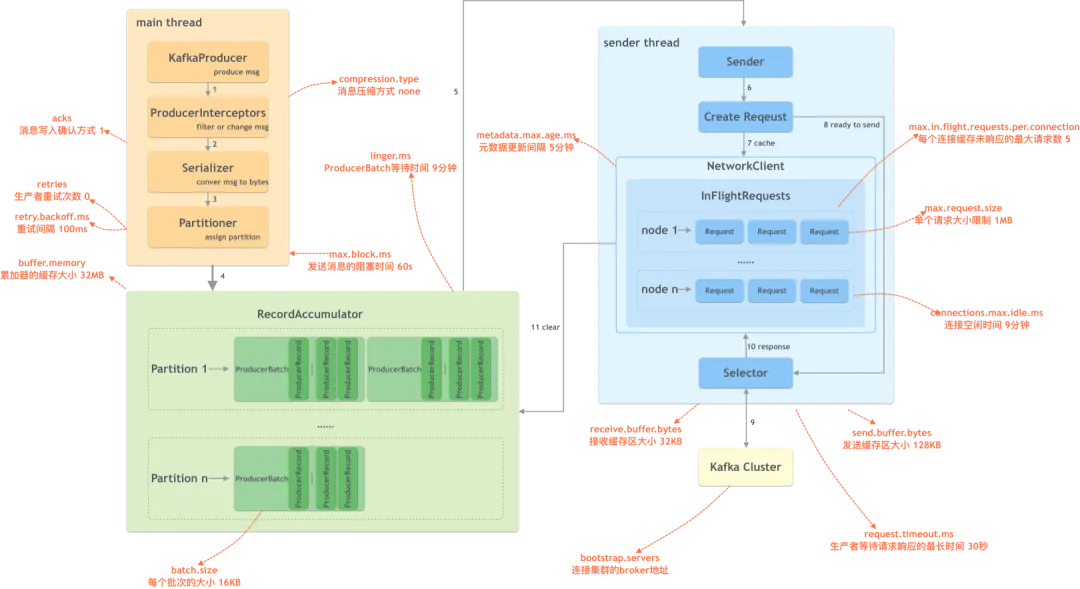
Producer
Steps:
- KafkaProducer 创建消息;
- 生产者拦截器在消息发送之前做一些准备工作,比如过滤不符合要求的消息、修改消息的内容等;
- 序列化器将消息转换成字节数组的形式;
- 分区器计算该消息的目标分区,然后数据会存储在 RecordAccumulator 中;
- 发送线程获取数据进行发送;
- 创建具体的请求;
- 如果请求过多,会将部分请求缓存起来;
- 将准备好的请求进行发送;
- 发送到 kafka 集群;
- 接收响应;
- 清理数据。
Configuration:
buffer.memory- the max size ofRecordAccumulatorbatch.size- the composite message batch sizelinger.ms- how long will the messages be pending while the batch is not full-filledmax.block.ms- how long will block producer from producing more data, while thebuffer.memoryis fullmax.in.flight.requests.per.connectionmax.request.size
Storage
SST, Sparse Index (timestamp), SendFile
Replication
- AR - Assigned Replicas
- ISR: in sync
- OSR: out of sync
- LEO: log end offset
- HW: high watermark
- smallest LEO in all ISRs
interview problems
Why Kafka is used in tech industry why it so popular?
- high throughput and low latency
- kafka can handle large volumes of messages quickly, making suitable for real-time data processing
- scalability
- kafka’s distributed architecture allows it to scale horizontally, accomodating growing data needs by adding more nodes
- fault tolerance and reliability
- kafka ensures data durability and reliability through replication and partitioning, maintaining operations even if some nodes fail
- stream processing
- kafka streams enables building complex real-time data processing applications
- data integration
- kafka acts as a central hub, integrating data from various sources and distributing it to multiple systems
- open-suorce and community support
- kafka benefits from a large, active comminuty that continously improves and expands its capabilities
- versatile use cases
- kafka is used for log aggregation, real-time analytics, event sourcing, messaging and metrics collection
- compatibility with big data ecosystems
- kafka integrates well with technologies like Hadoop, Spark, es, facilitating comprehensive data pipelines
- streamlined data processing
- kafak enables asynchonous processing, enhancing system performance and reliability
how does kafka ensure durability and fault tolerance
- topics and partitions
- replication factor
- leader and follower
- data persistence
- leader failure and recovery
- producer acknowledgement
- acks=all
- waits for ack from all replicas before considering the write successful
- acks=1
- waits for ack from leader only
- no_ack
- acks=all
References
- 如何更好地使用 Kafka?
- 腾讯云出品的,关于 Kafka 调优方式的文章
- Kafka 核心原理的秘密,藏在这 19 张图里!
- kafka interview questions