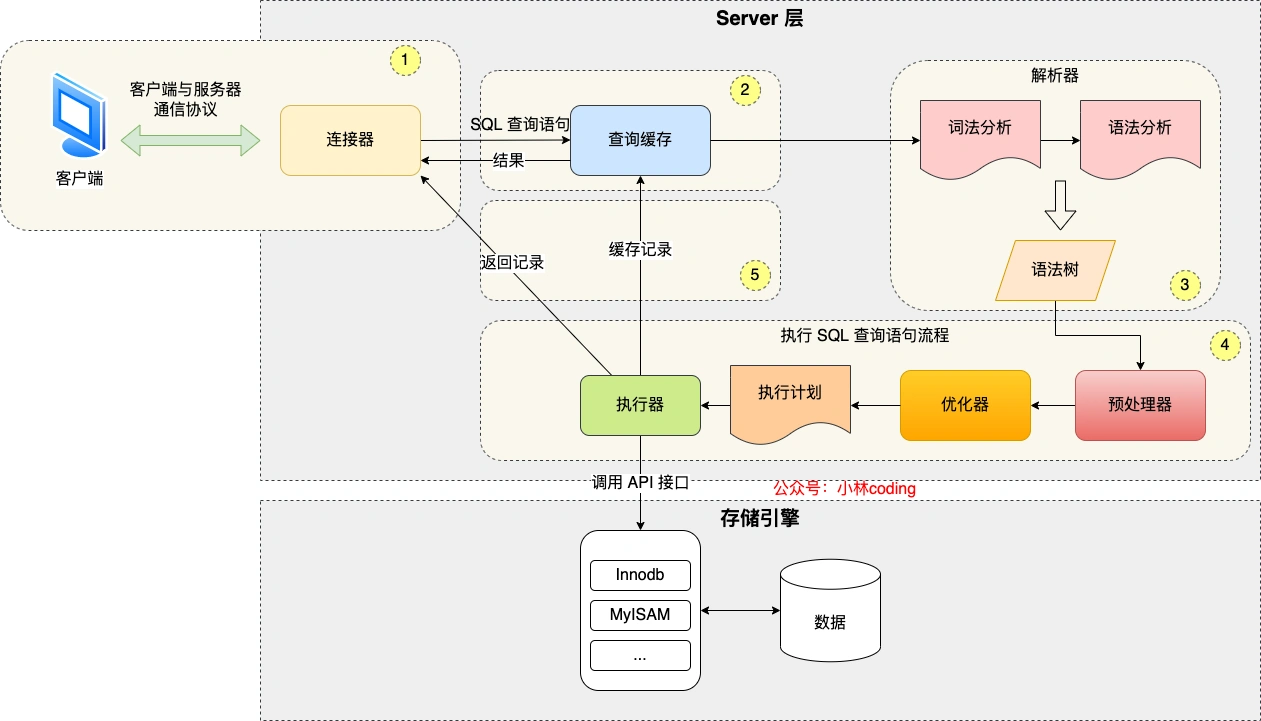
一款开源且流行的关系型数据库。
索引
LOG
优化相关知识点
表设计准则
命名规范
表名、字段名必须使用小写字母或者数字,禁止使用数字开头,禁止使用拼音,并且一般不使用英文缩写。
主键索引名为pk_字段名;唯一索引名为uk_字段名;普通索引名则为idx_字段名。
选择合适的字段类型
- 尽可能选择存储空间小的字段类型,就好像数字类型的,从
tinyint、smallint、int、bigint从左往右开始选择 - 小数类型如金额,则选择
decimal,禁止使用float和double。 - 如果存储的字符串长度几乎相等,使用
char定长字符串类型。 varchar是可变长字符串,不预先分配存储空间,长度不要超过5000。- 如果存储的值太大,建议字段类型修改为
text,同时抽出单独一张表,用主键与之对应。 - 同一表中,所有
varchar字段的长度加起来,不能大于65535. 如果有这样的需求,请使用TEXT/LONGTEXT类型。
主键设计要合理
uuid 或者是 auto_increment
选择合适的字段长度
varchar 字段长度一般设置为 2 的幂
优先考虑逻辑删除,而不是物理删除
- 为什么不推荐使用物理删除,因为恢复数据很困难
- 物理删除会使自增主键不再连续
- 核心业务表 的数据不建议做物理删除,只适合做状态变更。
每个表都需要添加这几个通用字段
- id:主键,一个表必须得有主键,必须
- create_time:创建时间,必须
- modifed_time/update_time: 修改时间,必须,更新记录时,需要更新它
- version : 数据记录的版本号,用于乐观锁,非必须
- remark :数据记录备注,非必须
- modified_by :修改人,非必须
- creator :创建人,非必须
一张表的字段不宜过多
如果一张表的字段过多,表中保存的数据可能就会很大,查询效率就会很低。
尽可能使用 Not Null 定义字段
- 首先,
NOT NULL可以防止出现空指针问题。 - 其次,
NULL值存储也需要额外的空间的,它也会导致比较运算更为复杂,使优化器难以优化 SQL。 NULL值有可能会导致索引失效- 如果将字段默认设置成一个空字符串或常量值并没有什么不同,且都不会影响到应用逻辑, 那就可以将这个字段设置为
NOT NULL。
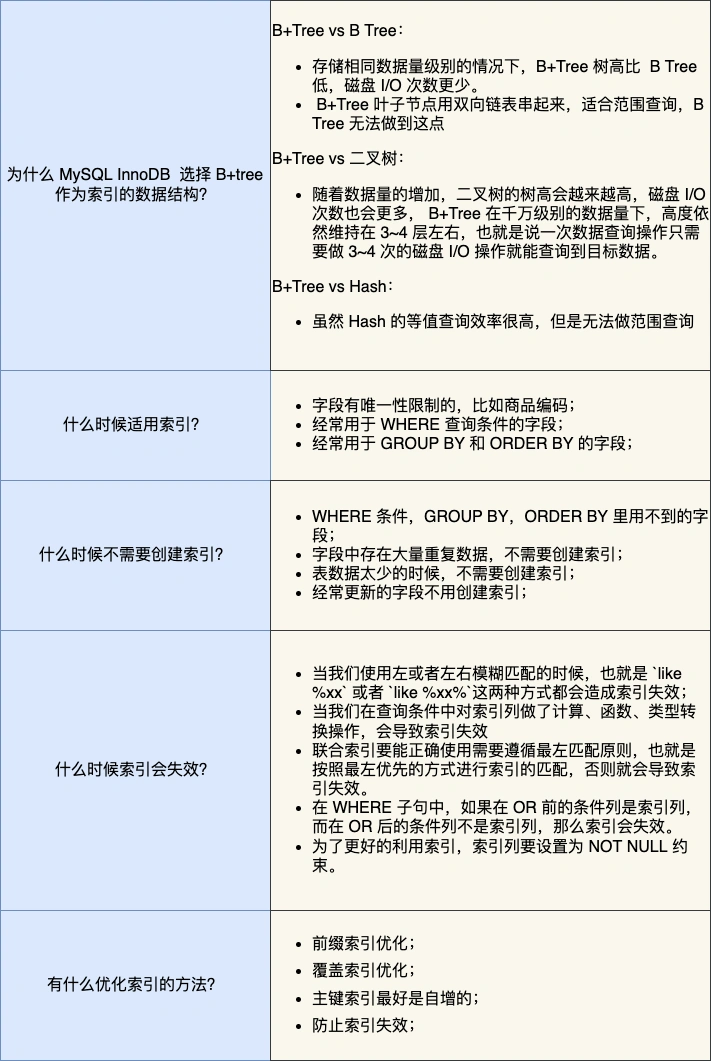
设计表时,评估哪些字段需要加索引
- 索引也不要建得太多,一般单表索引个数不要超过
5个。因为创建过多的索引,会降低写得速度。 - 区分度不高的字段,不能加索引,如性别等
- 索引创建完后,还是要注意避免索引失效的情况,如使用 mysql 的内置函数,会导致索引失效的
- 索引过多的话,可以通过联合索引的话方式来优化。然后的话,索引还有一些规则,如覆盖索引,最左匹配原则等等。
不需要严格遵守 3NF,通过业务字段冗余来减少表关联
- 第一范式:对属性的原子性,要求属性具有原子性,不可再分解;
- 第二范式:对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
- 第三方式:对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
避免使用 MySQL 保留字
如果库名、表名、字段名等属性含有保留字时,SQL语句必须用反引号来引用属性名称,这将使得 SQL 语句书写、SHELL 脚本中变量的转义等变得非常复杂。
不使用外键关联
- 使用外键存在性能问题、并发死锁问题、使用起来不方便等等。每次做
DELETE或者UPDATE都必须考虑外键约束,会导致开发的时候很难受,测试数据造数据也不方便。 - 还有一个场景不能使用外键,就是分库分表。
优先选择 InnoDB 存储引擎
选择统一合适的字符集
数据库库、表、开发程序等都需要统一字符集,通常中英文环境用utf8。
MySQL 支持的字符集有utf8、utf8mb4、GBK、latin1等。
- utf8:支持中英文混合场景,国际通过,3 个字节长度
- utf8mb4: 完全兼容 utf8,4 个字节长度,一般存储emoji 表情需要用到它。
- GBK :支持中文,但是不支持国际通用字符集,2 个字节长度
- latin1:MySQL 默认字符集,1 个字节长度
注释清楚枚举类型的数据库字段
时间的类型选择
对于 MySQL 来说,主要有date、datetime、time、timestamp 和 year。
- date :表示的日期值, 格式
yyyy-mm-dd,范围1000-01-01 到 9999-12-31,3 字节 - time :表示的时间值,格式
hh:mm:ss,范围-838:59:59 到 838:59:59,3 字节 - datetime:表示的日期时间值,格式
yyyy-mm-dd hh:mm:ss,范围1000-01-01 00:00:00到9999-12-31 23:59:59```,8 字节,跟时区无关 - timestamp:表示的时间戳值,格式为
yyyymmddhhmmss,范围1970-01-01 00:00:01到2038-01-19 03:14:07,4 字节,跟时区有关 - year:年份值,格式为
yyyy。范围1901到2155,1 字节
不建议使用 Stored Procedure
什么是存储过程
已预编译为一个可执行过程的一个或多个 SQL 语句。
什么是触发器
触发器,指一段代码,当触发某个事件时,自动执行这些代码。使用场景:
- 可以通过数据库中的相关表实现级联更改。
- 实时监控某张表中的某个字段的更改而需要做出相应的处理。
- 例如可以生成某些业务的编号。
- 注意不要滥用,否则会造成数据库及应用程序的维护困难。
对于 MYSQL 来说,存储过程、触发器等还不是很成熟, 并没有完善的出错记录处理,不建议使用。
1:N 关系的设计
有时候两张表存在N:N关系时,我们应该消除这种关系。通过增加第三张表,把N:N修改为两个 1:N。
大字段
在 MySQL 中,保存大字段(博客内容)的设计方案,其实是不太合理的。这种非常大的数据,可以保存到mongodb中,然后,在业务表保存对应mongodb的id即可。
考虑是否需要分库分表
数据量太大的话,SQL 的查询就会变慢。
SQL 编写的一些优化建议
- 查询 SQL 尽量不要使用
select *,而是select具体字段 - 如果知道查询结果只有一条或者只要最大/最小一条记录,建议用
limit 1 - 应尽量避免在
where子句中使用or来连接条件 - 注意优化
limit深分页问题 - 使用
where条件限定要查询的数据,避免返回多余的行 - 尽量避免在索引列上使用
mysql的内置函数 - 应尽量避免在
where子句中对字段进行表达式操作 - 应尽量避免在
where子句中使用!=或<>操作符 - 使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。
- 对查询进行优化,应考虑在
where 及 order by涉及的列上建立索引 - 如果插入数据过多,考虑批量插入
- 在适当的时候,使用覆盖索引
- 使用 explain 分析你 SQL 的计划
Instructions
The execution of an update operation
- The transaction starts and the update statement is executed.
- The changes are made to the InnoDB storage engine’s buffer pool in memory.
- The redo log buffer is updated with the changes made to the buffer pool.
- The redo log buffer is periodically flushed to disk to ensure that the changes are durable.
- If binary logging is enabled, the binary log is updated with the changes made to the buffer pool.
- The transaction is committed and the changes are made permanent.
In the event of a crash, the redo logs are used to recover the changes made to the buffer pool and ensure data consistency. The binary logs are used for replication and point-in-time recovery, allowing you to restore a database to a specific state in the past.
redo log flush timing
- When the redo log buffer becomes full: The redo log buffer is periodically flushed to disk when it becomes full to ensure that changes are durable.
- When a transaction is committed: When a transaction is committed, the redo log buffer is flushed to disk to ensure that the changes made during the transaction are durable.
- When a checkpoint occurs: A checkpoint is a process that periodically writes dirty pages from the InnoDB buffer pool to disk. When a checkpoint occurs, the redo log buffer is flushed to disk.
- When the server is shut down: When the MySQL server is shut down, the redo log buffer is flushed to disk to ensure that any changes made to the buffer pool are durable.
Usages
insert with select
|
|
MISC
count efficiency
|
|
更新一条记录的流程
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录:
- 如果 id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
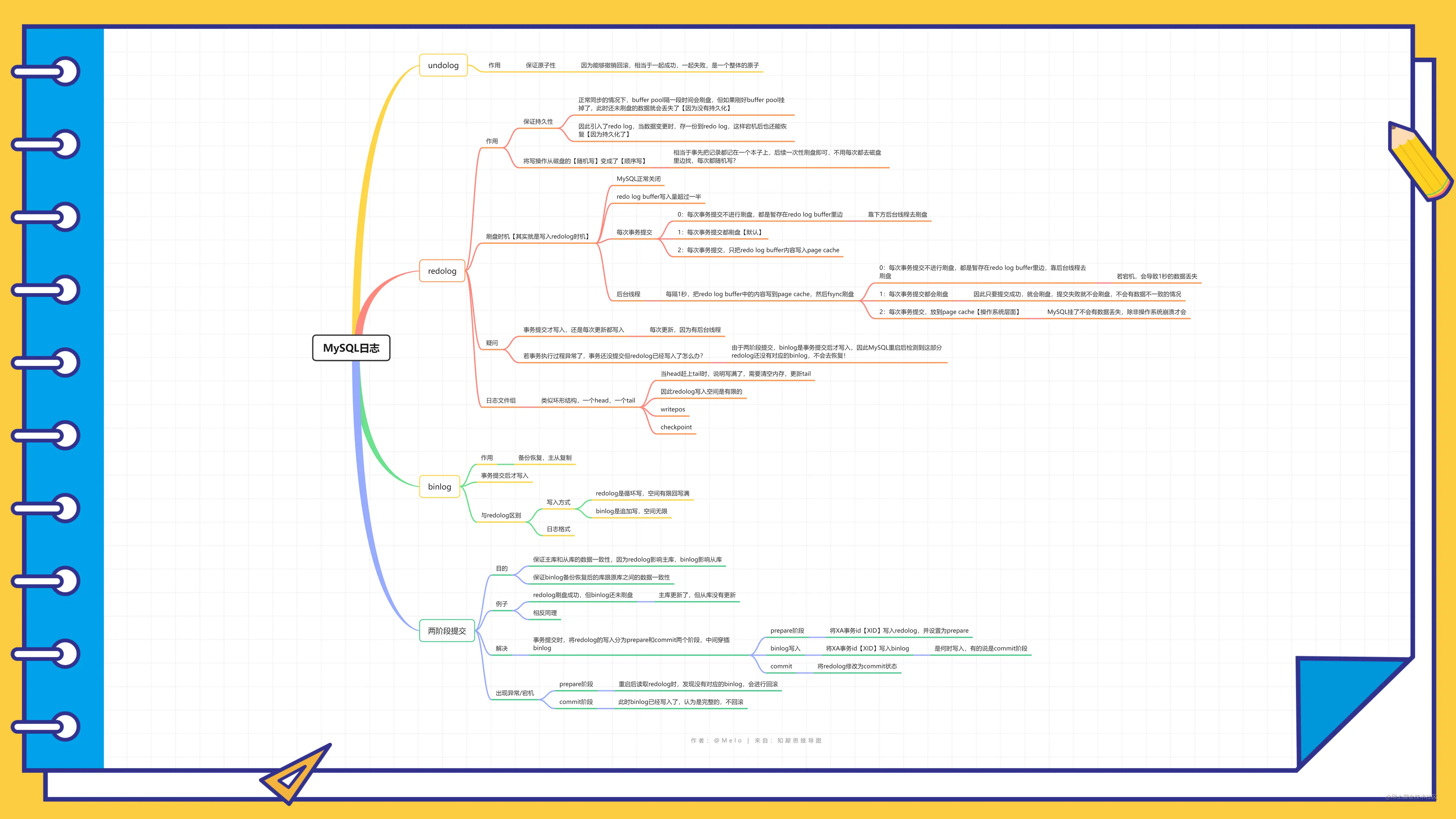
- 开启事务, InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘 I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
- 事务提交(为了方便说明,这里不说组提交的过程,只说两阶段提交):
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
- 至此,一条更新语句执行完成。
Interview Questions
int(10) char(10)
- int(10) 是显示数据的长度
- char(10) 是存储数据的长度
truncate, delete
DELETE |
TRUNCATE |
|
|
The DELETE command is used to delete particular records from a table. |
Definition |
The TRUNCATE command is used to delete the complete data from the table. |
|
It is a DML command. |
Language Type |
It is a DDL command |
|
The DELETE command acquires the lock on every deleting record; thus, it requires more locks and resources. |
Locks and Resources |
The TRUNCATE command requires fewer locks and resources before deleting the data page because it acquires the lock on the data page |
|
It works with the WHERE clause. |
WHERE Clause |
It does not work with the WHERE clause. |
|
DELETE operation operates on data records and executes deletion one-by-one on records in the order of the queries processed |
Working |
TRUNCATE operates on data pages and executes deletion of the whole table data at a time. |
|
Its speed is slow as it makes operations in rows and records it in transaction logs |
Speed |
Its speed is fast as it only records data pages in transaction logs. |
|
It records all the deleted data rows in the transaction log. |
Transaction Log |
It records only the deleted data pages in the transaction log. |
|
You can restore the data using the COMMIT or ROLLBACK command. |
Rollback |
You cannot restore the deleted data after executing this command. |
|
The DELETE statement deletes the records and does not interfere with the table's identity. |
Table Identity |
The TRUNCATE statement does not delete the table structure but resets the identity of the table |
|
It works with an indexed view. |
Indexed View |
It does not work with indexed views. |
|
It activates the triggers on the table and causes them to fire |
Triggers |
It does not activate the triggers applied on the table. |