- Athena
- Redshift
- OLAP (PostgreSQL)
- OpenSearch
- EMR (Elastic Map Reduce)
- QuickSight
- Glue
- LakeFormation
- Kinesis
- MSK (Managed Streaming for Apache Kafka)
- Big Data Ingestion Pipeline
Athena
- Serverless query service to analyze data stored in Amazon S3
- standard SQL language to query files (
Presto) - supports CSV, JSON, ORC, Avro, Parquet
- $5.00 per TB of data scanned
- with Amazon QuickSight for reporting/dashboards
- use cases
- business intelligence / analytics / reporting
- analyze & query VPC flow logs, ELB logs, CloudTrail trails…
- performance improvements
- use columnar data for cost saving (less scan)
- Parquet, ORC
- use
Glueto convert your data
- compress data for smaller retrievals
- partition datasets for easy querying on virtual columns
s3://athena-examples/flight/parquet/year=1991/month=1/day=1 - use larger files (> 128MB) to minimize overhead
- use columnar data for cost saving (less scan)
- federated query
- allows you to run SQL queries across data stored in relational, non-relational, object, and custom data sources
- uses data source connectors that run on AWS lambda to run federated queries
- store the results back in S3
Redshift
- Redshift is based on PostgreSQL, but it’s not used for OLTP
- It’s OLAP – online analytical processing (analytics and data warehousing)
- 10x better performance than other data warehouses, scale to PBS of data
- Columnar storage of data (instead of row based) & parallel query engine
- Pay as you go based on the instances provisioned
- Has a SQL interface for performing the queries
- BI tools such as Amazon QuickSight or Tableau integrate with it
- vs Athena: faster queries / joins / aggregations thanks to indexes
- redshift cluster
- leader node - for query planning, results aggregation
- compute node - for performing the queries, send results to leader
- provision the node size in advance
- use Reserved Instances for cost savings
- snapshots & DR
- has “multi-AZ” mode for some clusters
- snapshots are point-in-time backups of a cluster, stored internally in S3
- snapshots are incremental
- capable of restoring a snapshot into a new cluster
- automated - every 8 hours, every 5GB, or on a schedule. set retention between 1 ~ 35 days
- manual - snapshot is retained until you delete it
- you can configure Redshift to automatically copy snapshots to another Region
- loading data into redshift
- Large inserts are much better
- Redshift Spectrum
- query data that is already in S3 without loading it
- must have a redshift cluster available to start the query
- the query is then submitted to thousands of redshift spectrum nodes
OpenSearch
- With OpenSearch, you can search any field, even partially matches
- It’s common to use OpenSearch as a complement to another database
- Two modes: managed cluster or serverless cluster
- Does not natively support SQL (can be enabled via a plugin)
- Ingestion from Kinesis Data Firehose, AWS IoT, and CloudWatch Logs
- Security through Cognito & IAM, KMS encryption,TLS
- Comes with OpenSearch Dashboards (visualization) (
kibana) - patterns
- dynamoDB table -> dynamoDB streams -> lambda function -> OpenSearch
- CloudWatch logs -> subscription filter -> lambda (realtime) / kinesis data firehose (near realtime) -> OpenSearch
EMR
- EMR stands for “Elastic MapReduce”
- EMR helps creating Hadoop clusters (Big Data) to analyze and process vast amount of data
- The clusters can be made of hundreds of EC2 instances
- EMR comes bundled with Apache Spark, HBase, Presto, Flink…
- EMR takes care of all the provisioning and configuration
- Auto-scaling and integrated with Spot instances
- Use cases: data processing, machine learning, web indexing, big data…
- node types
- master node - manage the cluster, coordinate, manage health - long running
- core node - run tasks and store data - long running
- task node - just to run task, usually spot
QuickSight
- Serverless machine learning-powered business intelligence service to create interactive dashboards
- Fast, automatically scalable, embeddable, with per-session pricing
- Use cases:
- Business analytics
- Building visualizations
- Perform ad-hoc analysis
- Get business insights using data
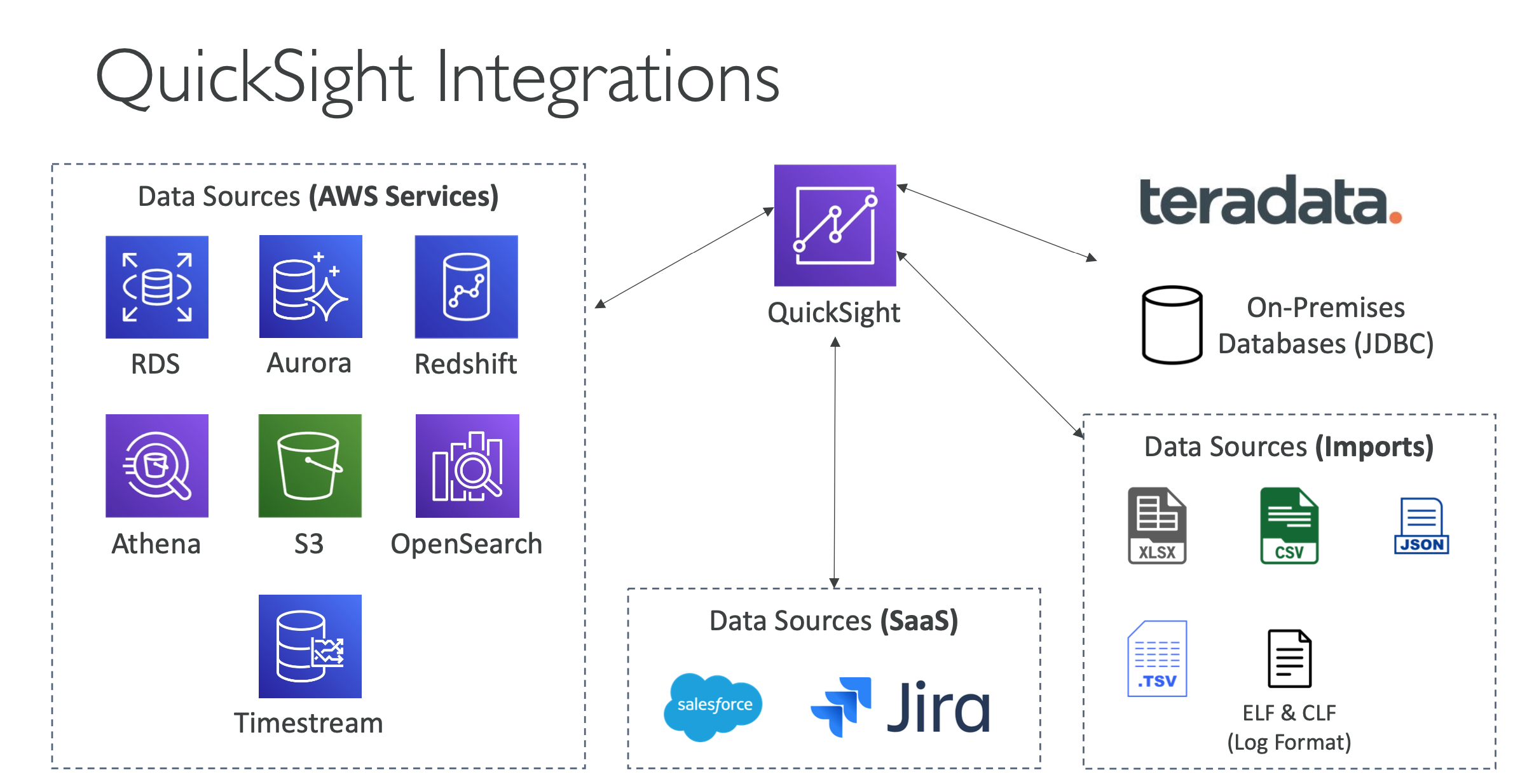
- Integrated with RDS, Aurora, Athena, Redshift, S3…
- In-memory computation using SPICE engine if data is imported into QuickSight
- Enterprise edition: Possibility to setup Column-Level security (CLS)
- dashboard & analysis
- users (standard version) and groups (enterprise version)
- users & groups only exist within QuickSight
- dashboard is a read-only snapshot of an analysis, preserves the configuration of the analysis (filtering, parameters, controls, sort)
- share the analysis or dashboard with users or groups
- user who see the dashboard can also see the underlying data
- users (standard version) and groups (enterprise version)
Glue
- Managed extract, transform, load (ETL) service
- fully serverless service
- use cases
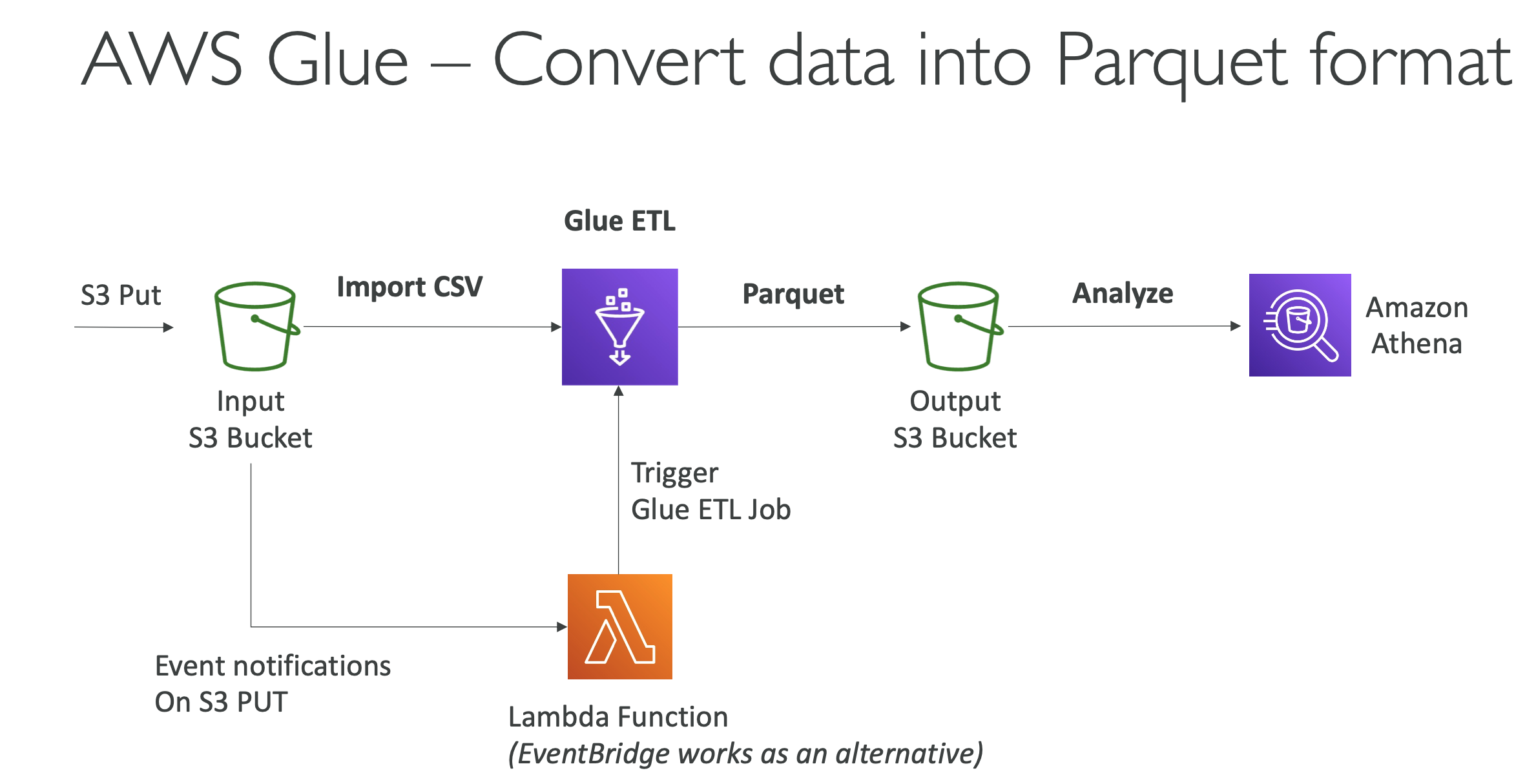
- convert data into parquet format
- catalog of dataset
- high level things
- job bookmarks - prevent re-processing old data
- elastic views
- combine and replicate data across multiple data stores using SQL
- glue monitors for changes in the source data, serverless
- leverages a “virtual table”
databrew- clean and normalize data using pre-built transformation- studio - new GUI to create, run and monitor ETL jobs
- streaming ETL - compatible with Kinesis data stream, Kafka, MSK
LakeFormation
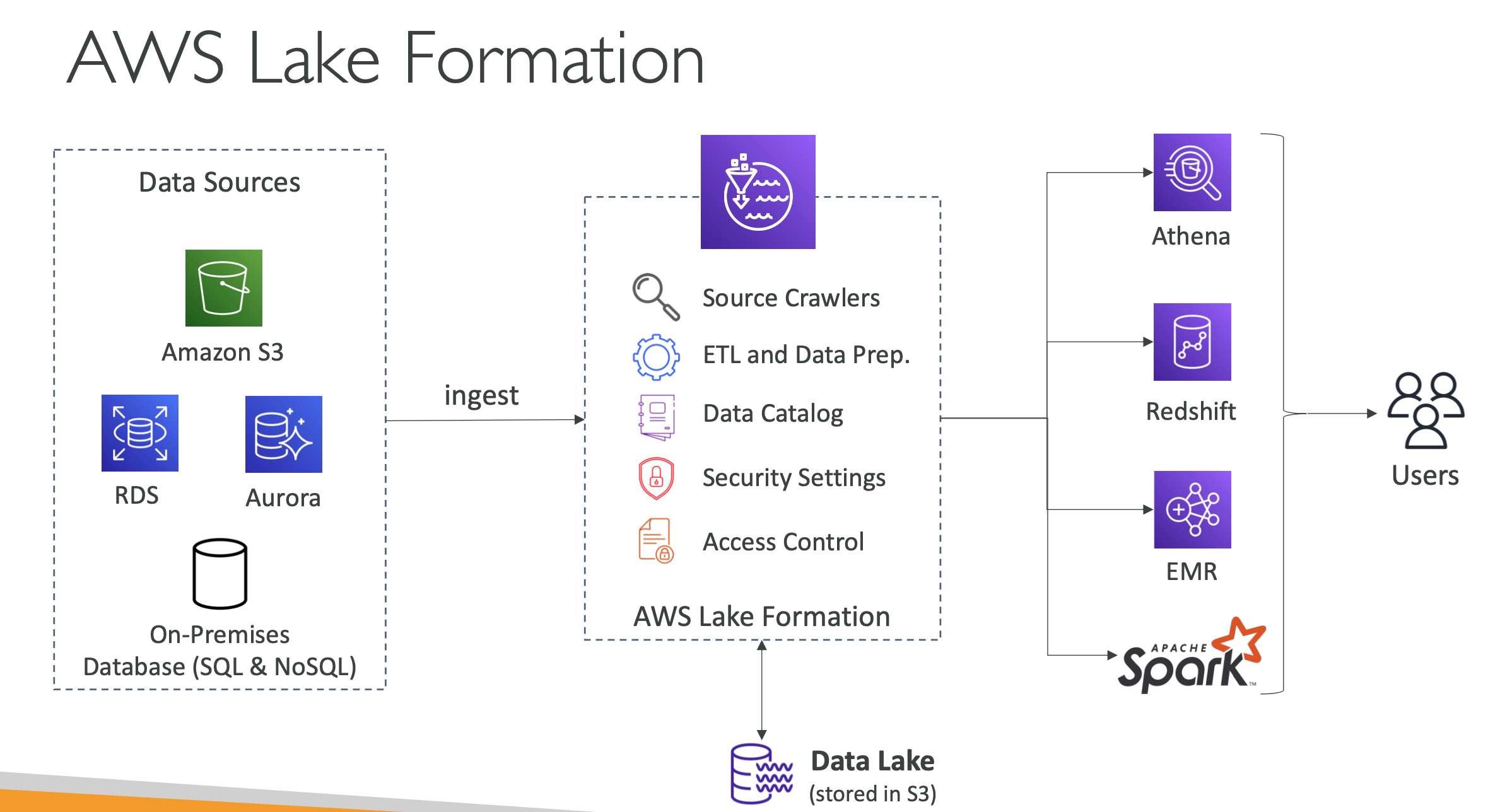
Centralized permission control (row / column level) (backed by S3)
- Data lake = central place to have all your data for analytics purposes
- Fully managed service that makes it easy to setup a data lake in days
- Discover, cleanse, transform, and ingest data into your Data Lake
- It automates many complex manual steps (collecting, cleansing, moving, cataloging data, …) and de-duplicate (using ML Transforms)
- Combine structured and unstructured data in the data lake
- Out-of-the-box source blueprints: S3, RDS, Relational & NoSQL DB…
- Fine-grained Access Control for your applications (row and column-level)
- Built on top of AWS Glue
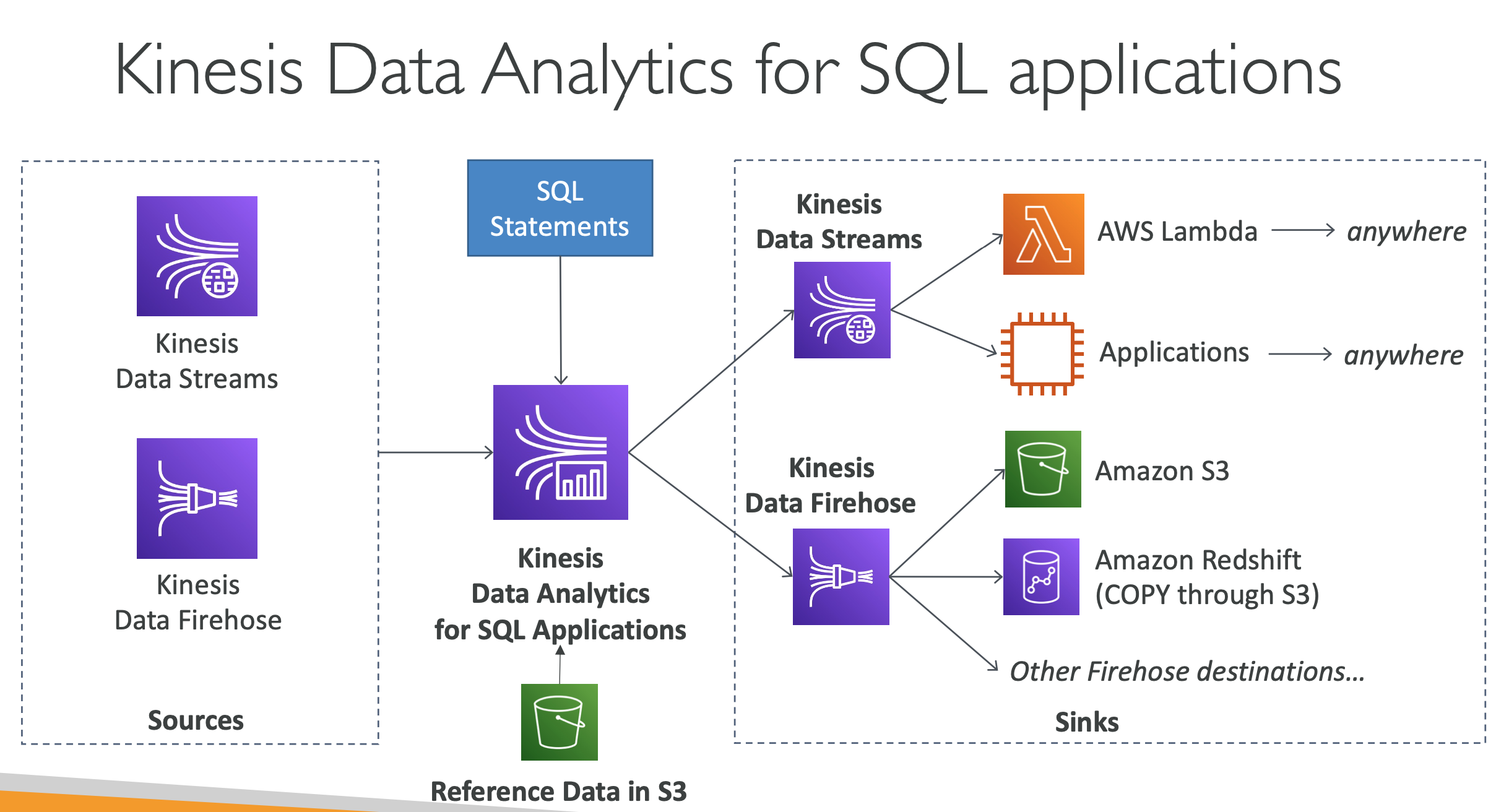
Kinesis data analytics
- Real-time analytics on Kinesis Data Streams & Firehose using SQL
- Add reference data from Amazon S3 to enrich streaming data
- Fully managed, no servers to provision
- Automatic scaling
- Pay for actual consumption rate
- Output:
- Kinesis Data Streams: create streams out of the real-time analytics queries
- Kinesis Data Firehose: send analytics query results to destinations
- Use cases:
- Time-series analytics
- Real-time dashboards
- Real-time metrics
MSK
- Alternative to Amazon Kinesis
- Fully managed Apache Kafka on AWS
- Allow you to create, update, delete clusters
- MSK creates & manages Kafka brokers nodes & Zookeeper nodes for you
- Deploy the MSK cluster in your VPC, multi-AZ (up to 3 for HA)
- Automatic recovery from common Apache Kafka failures
- Data is stored on EBS volumes for as long as you want
- MSK Serverless
- Run Apache Kafka on MSK without managing the capacity
- MSK automatically provisions resources and scales compute & storage
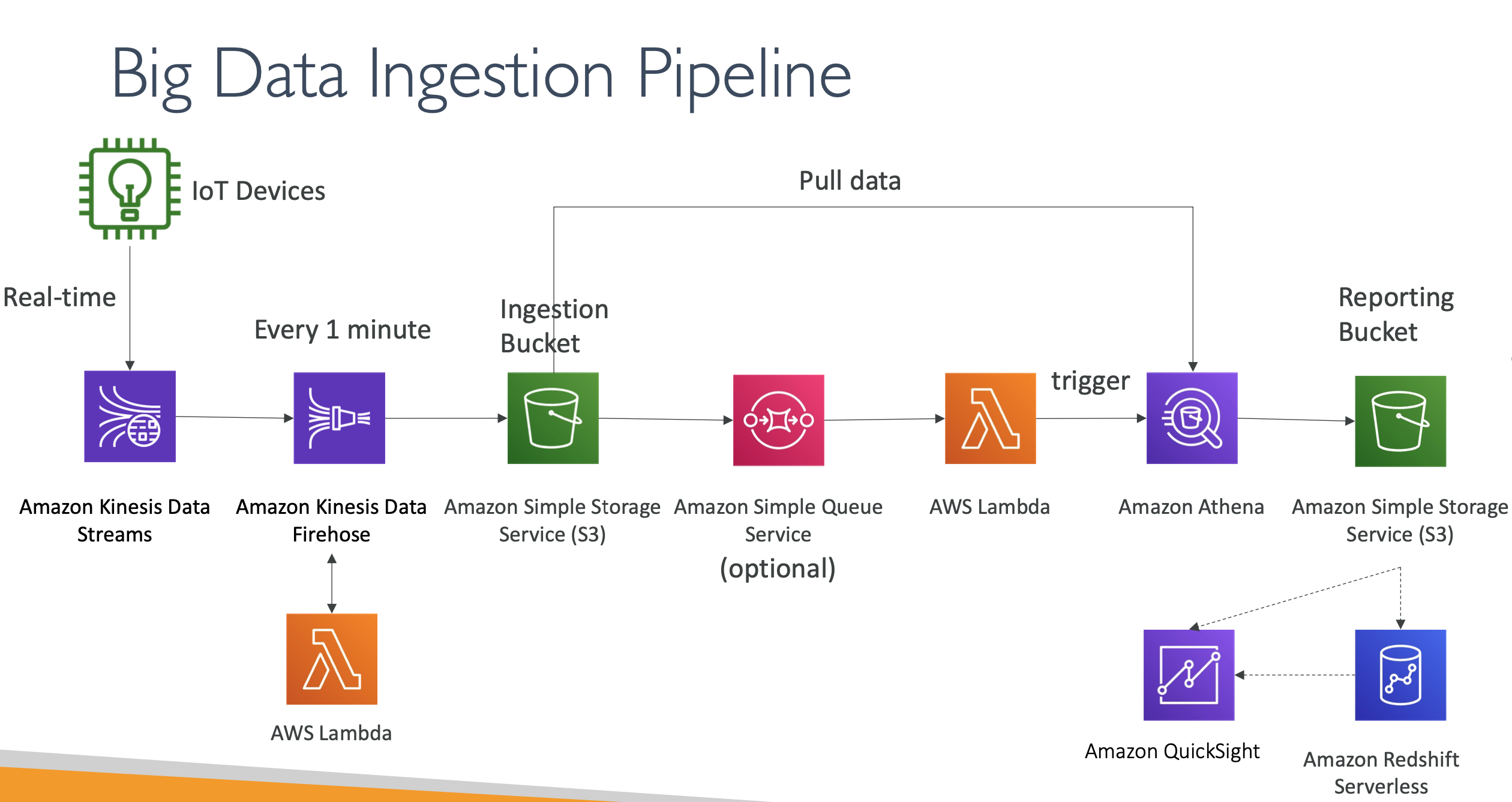
Big Data Ingestion Pipeline
- IoT Core allows you to harvest data from IoT devices
- Kinesis is great for real-time data collection
- Firehose helps with data delivery to S3 in near real-time (1 minute)
- Lambda can help Firehose with data transformations
- Amazon S3 can trigger notifications to SQS
- Lambda can subscribe to SQS (we could have connecter S3 to Lambda)
- Athena is a serverless SQL service and results are stored in S3
- The reporting bucket contains analyzed data and can be used by reporting tool such as AWS QuickSight, Redshift, etc…