- 简单动态字符串
- 双向链表
- 压缩列表
- 哈希表
- 跳表
- 整数数组
- global hash table 保存了所有的键值对
- 双全局表
- 渐进式 rehash (以保证分布均匀, 查询效率)
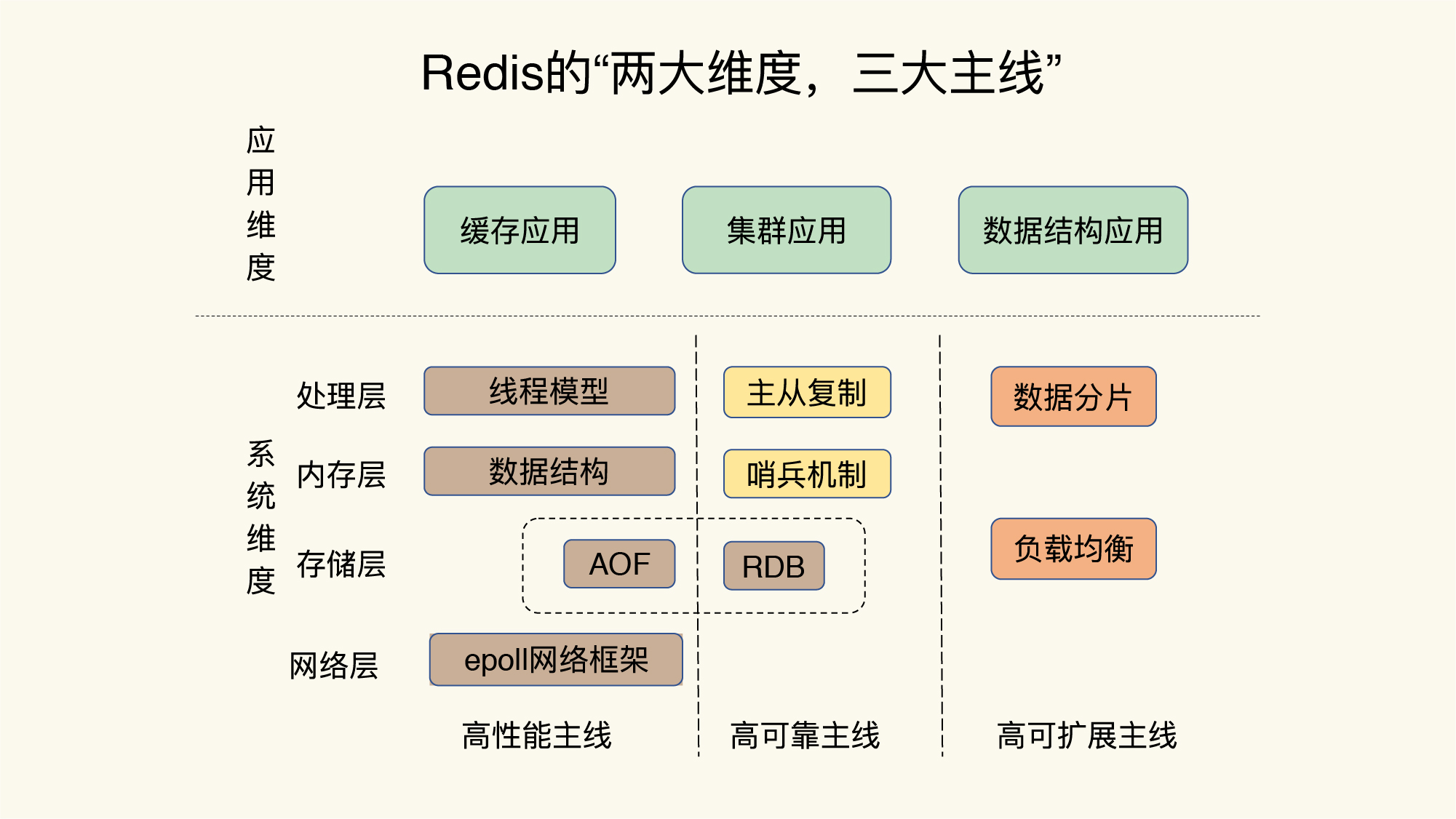
基于多路复用的高性能 IO 模型
modules
- index (hash, skiplist)
- storage (allocator, durability)
- high available (master/slave, sentinel)
- high extensive (data sharding)
Redis Concepts
- AOF
- 为了避免额外的检查开销, Redis 在向 AOF 里面记录日志的时候, 并不会去对这些命令进行语法检查; 在命令执行后才记录日志, 不会阻塞当前的写操作
- Always, EverySec, No (刷盘时机由操作系统控制)
- AOF 重写机制 后台线程 bgrewriteaof, 类似于 SST 压缩
- RDB Snapshot
- save, bgsave – COW (旧版本数据备份)
- 主从复制 (replicaof)
- steps
- 主从库建立连接、协商同步 (psync, FULLRESYNC[runId, offset])
- 主库将所有数据同步给从库 (RDB)
- 主库把第二阶段执行过程中新收到的写命令, 在发送给从库
- 网络波动 - 异常
- prev 2.8 主从全量复制
- post 2.8 增量复制 repl_backlog_buffer 缓冲区 (buffer + offset)
- repl_backlog_buffer 是一个环形缓冲区, 主库会记录自己写到的位置, 从库会记录自己已经读到的位置
- steps
哨兵
- 监控
- 选主
- 通知
- 主观下线/客观下线 - down-after-milliseconds - N/2+1
主库宕机, 从库选举依据
- 优先级
- 与旧主库同步程度最接近
- ID 小的从库得分高 (1,2 一致的情况下)
- 基于 pub/sub 机制的哨兵集群
__sentinel__:hello - 基于 INFO 命令的从库列表, 帮助哨兵和从库建立连接
- 基于哨兵自身的 pub/sub 功能, 实现了客户端和哨兵之间的时间通知
要保证所有哨兵实例的配置是一致的, 尤其是主观下线的判断值 down-after-milliseconds
cluster
在手动分配哈希槽时, 需要把 16384 个槽都分配完, 否则 Redis 集群无法正常工作.
重定向机制 MOVED
redis 集合
- set (差集, 交集, 并集)
- sorted set 排序统计
- hash
- list
- bitmap 二值状态 - 精确统计, 内存开销大于 hyperloglog
- hyperloglog 概率统计, 基数统计
RESP (Redis Serialization Protocol)
- 命令
- SET/GET
- 键
- 单个值
- 集合值
- OK
- 整数回复
- LLEN
- 集合命令成功操作时, 实际变动的元素个数
- 错误信息
- error
- 具体的错误信息
RESP2 的五种编码类型
- 简单字符串类型
++OK\r\n
- 长字符串类型
$$9 testvalue\r\n
- 整数类型
::3\r\n
- errors
--ERR unknown command 'PUT'...
- arrays
**2\r\n$3\r\nGET\r\n$7\r\ntestkey\r\n
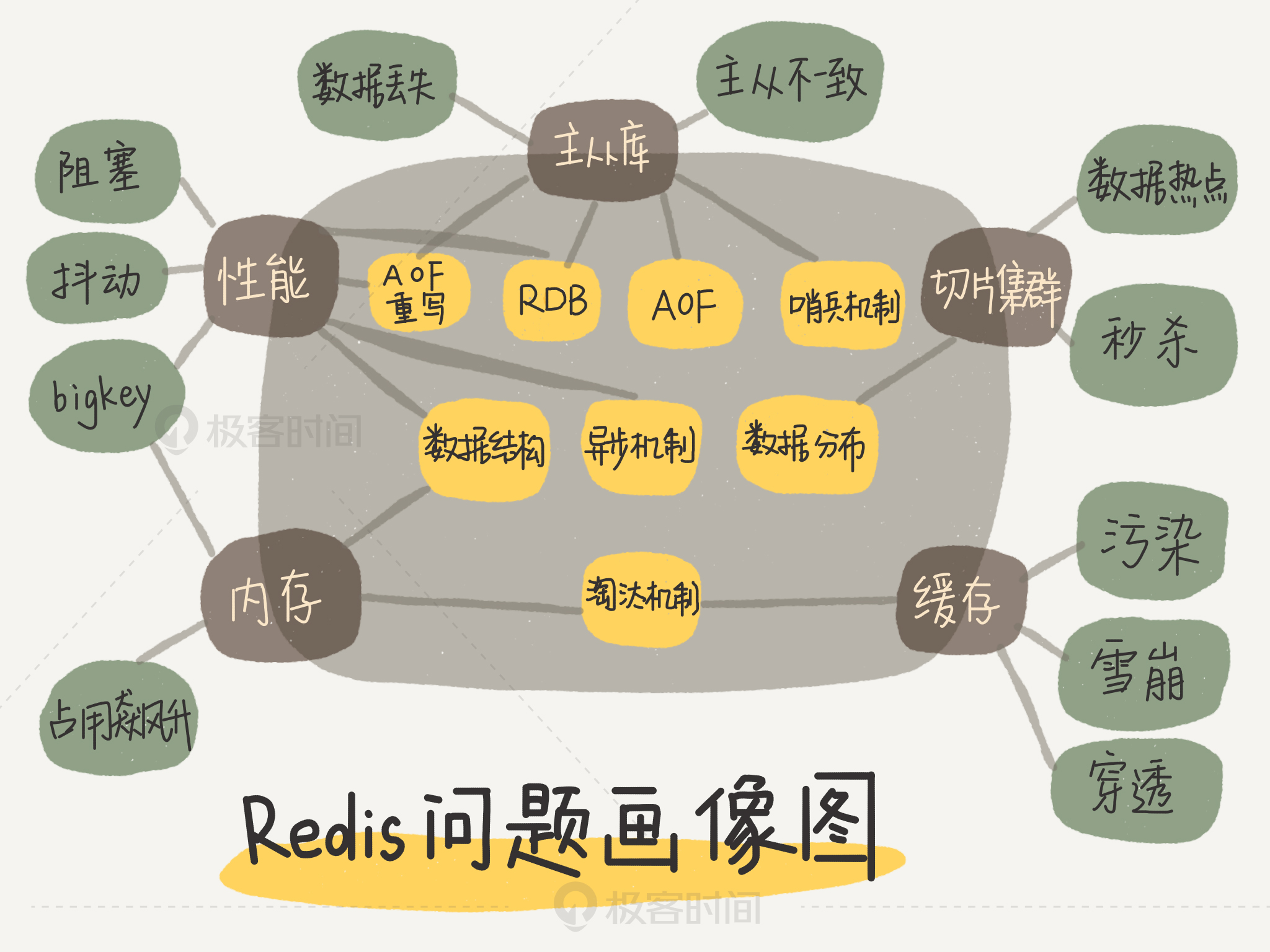
Redis Problems
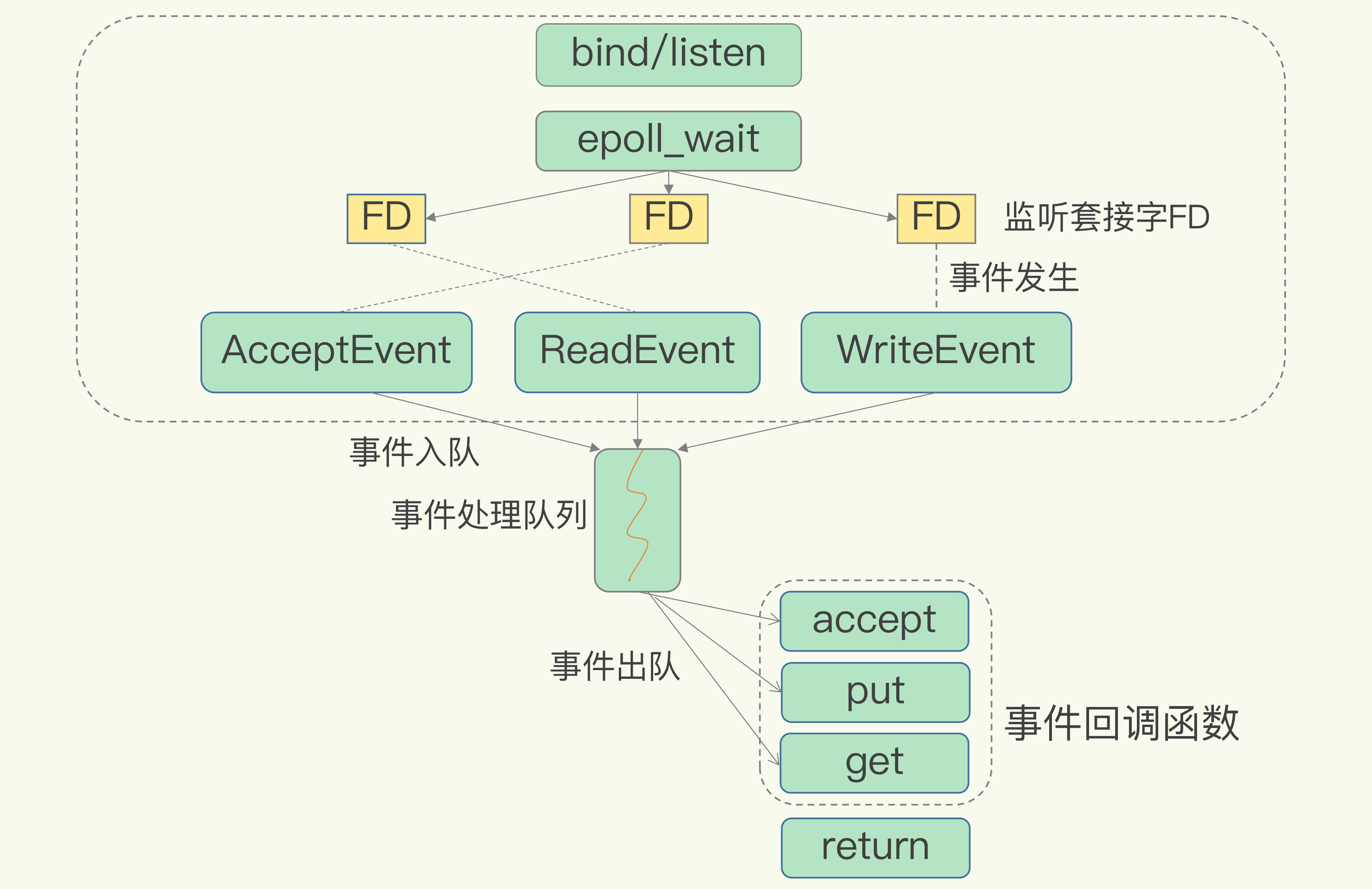
网络连接的处理、网络请求的解析,以及数据存取的处理,是用一个线程、多个线程,还是多个进程来交互处理呢?该如何进行设计和取舍呢?
单个核心线程处理 IO 事件, 采用了多路复用机制以避免单个客户端导致的阻塞. 同时有额外的线程来完成持久化、异步删除、集群数据同步等
单线程模型可以避免多线程带来的上下文切换开销, 以及并发访问控制问题.
Redis 单线程潜在的问题
- 大 key 操作
key *或者 get all -> scan- 大量的客户端连接
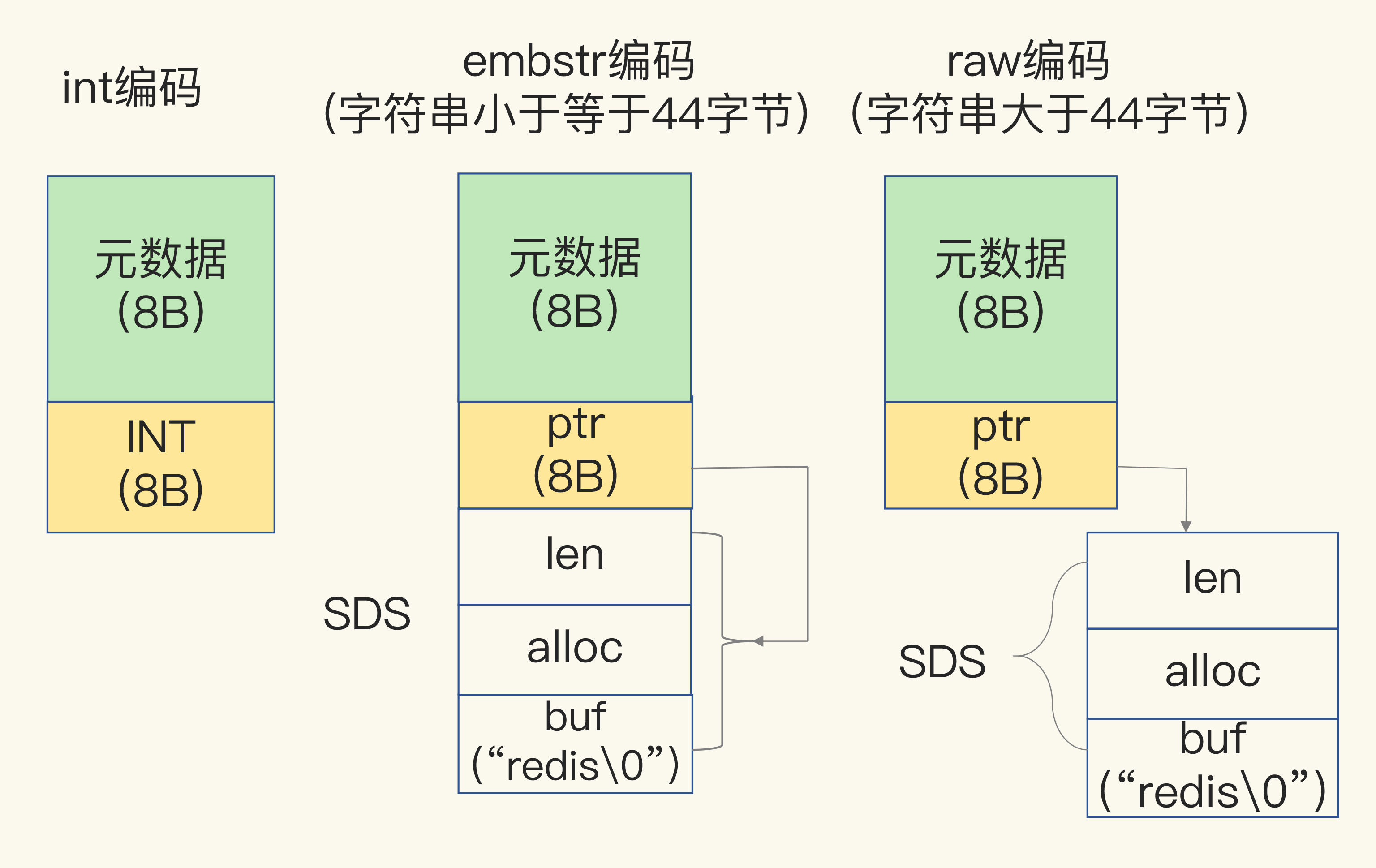
String 的额外开销
- 当保存 64 位有符号整数时, String 类型会保存为一个 8 字节的 Long 类型证书 (int 编码)
- 一旦数据中包含字符串, String 类型就会使用 Simple Dynamic String 来保存
- “\0” 额外 1 字节
- len 4 字节
- alloc 实际分配长度 4 字节
- RedisObject (类型信息, 算是一种 overhead, 用于区分 Redis 中的具体数据类型)
- 8 字节元数据
- type
- encoding
- lru
- refcount
- 8 字节指针 - SDS
- 8 字节元数据
possible blocking
- Redis 内部的 blocking 操作
- CPU 核和 NUMA 架构的影响
- Redis 核心系统配置
- Redis 内存碎片
- Redis 缓冲区
blocking points
- 客户端: 网络 IO, 键值对增删改查操作, 数据库操作
- 磁盘: 生成 RDB 快照, 记录 AOF 日志, AOF 日志重写
- 主从: 主库生成, 传输 RDB 文件, 从库接收 RDB 文件, 清空数据库, 加载 RDB 文件
- 切换集群实例: 向其他实例传输 hash 槽信息, 数据迁移
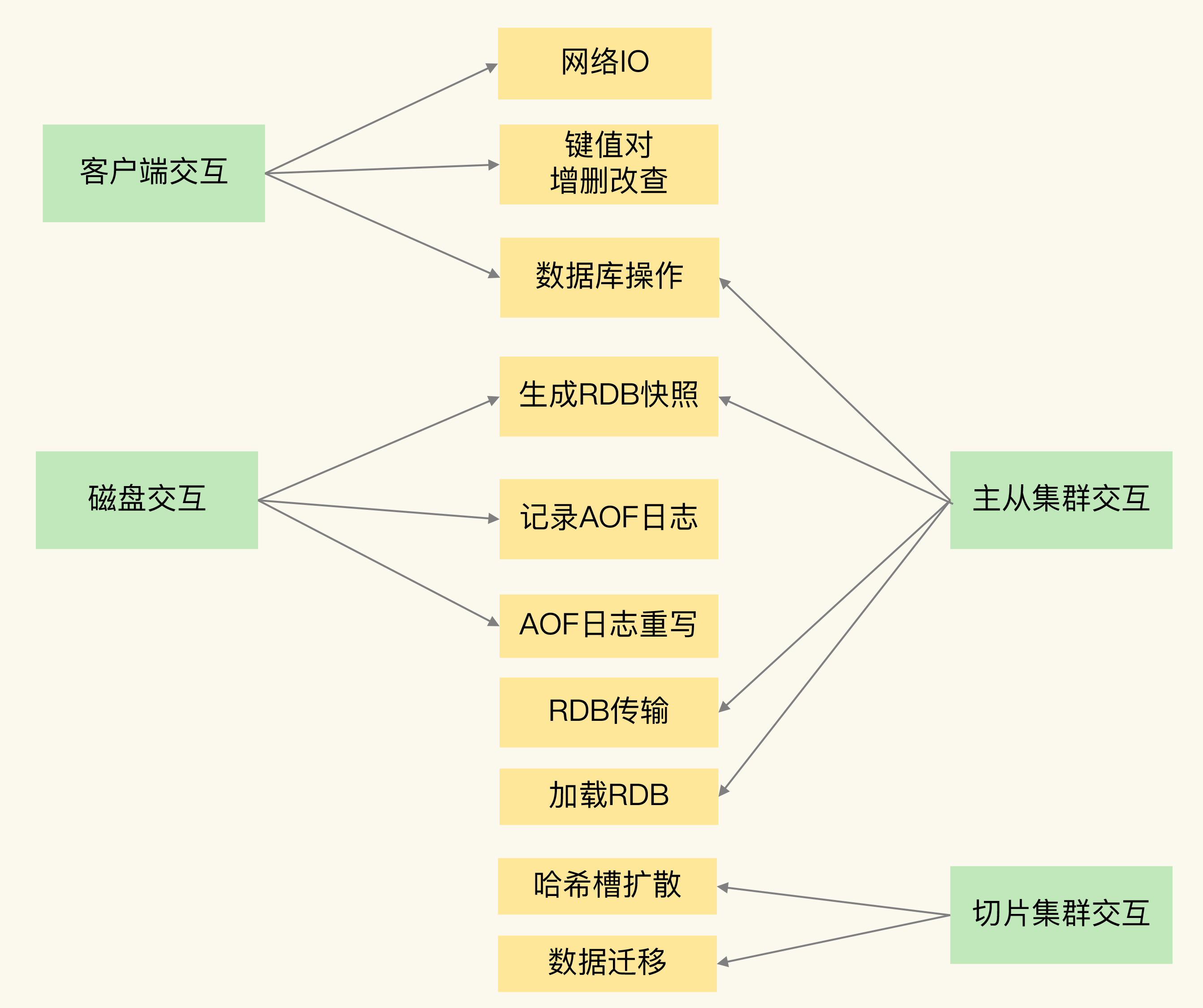
- 集合全量查询和聚合操作
- bigKey 删除
- 清空数据库
- AOF 日志同步写
- 从库加载 RDB 文件
sub-threads in redis
after redis 4.0 - pthread_create
- aof write
- key-value delete
- close file (async)
redis with cpu
NUMA to reduce context switch (socket change while processing redis)
slow redis
9 check list
- 获取 redis 实例在当前环境下的基线性能
- 是否用了慢查询命令 - redis-cli –intrinsic-latency
- 考虑采用其他命令替代
- 客户端聚合
- 是否对过期 key 设置了相同的过期时间
- 是否存在 bigkey?
- AOF 的配置级别是什么, 业务层面是否是强需求
- 磁盘压力过大, 阻塞 AOF 重写子进程, 进而阻塞住了 fsync 后台线程
- 实例内存使用是否过大, swap 如何
- 实例运行环境是否启用了透明大页机制
- 是否运行了 Redis 主从集群
- 把主库实例控制在 2~4GB, 以避免从库加载 RDB 文件导致阻塞
- 是否使用了多核 CPU 或 NUMA 架构的机器运行 Redis 实例
内存碎片
info memory, 三项指标, use_memory (应用所需)、used_memory_rss (实际分配)、mem_fragmentation_ratio 内存碎片率 (1-1.5 算是正常水平)
- 重启 Redis
- 启用内存碎片自动清理
- active-defrag-ignore-bytes 内存碎片的字节数达到 100MB, 开始清理
- active-defrag-threshold-lower 内存碎片空间占操作系统分配给 Redis 的总空间比例的 10%, 开始清理
- active-defrag-cycle-min 自动清理过程所用 CPU 时间的比例不低于 25%
- active-defrag-cycle-max 自动清理过程所用 CPU 时间的比例不高于 75%
缓冲区
CLIENT LIST (缓冲区溢出时, Redis 会主动关闭客户端连接)
- cmd: 客户端最新执行的命令
- qbuf: 输入缓冲区已经使用的大小
- qbuf-free: 输入缓冲区尚未使用的大小
输出缓冲区: 两部分, 一部分是大小为 16KB 的固定缓冲空间, 用来暂存 OK 响应和错误信息; 另一部分时可以动态调整空间的缓冲区域.
缓冲区溢出的三种情况
- 服务器返回 bigkey 的大量数据
- 执行了 MONITOR 命令
- 输出结果持续占用输出缓冲区
- 缓冲区大小设置不合理
- client-output-buffer-limit
复制缓冲区
在全量复制的过程中, 主节点在向从节点传输 RDB 文件时, 会继续接收客户端发送的写命令请求. 这些写命令就会先保存在复制缓冲区, 等 RDB 文件传输完成后, 再发送给从节点去执行. 如果在全量复制时, 从节点接收和加载 RDB 比较慢, 同时主节点接收到了大量的写命令, 就可能导致复制缓冲区溢出.
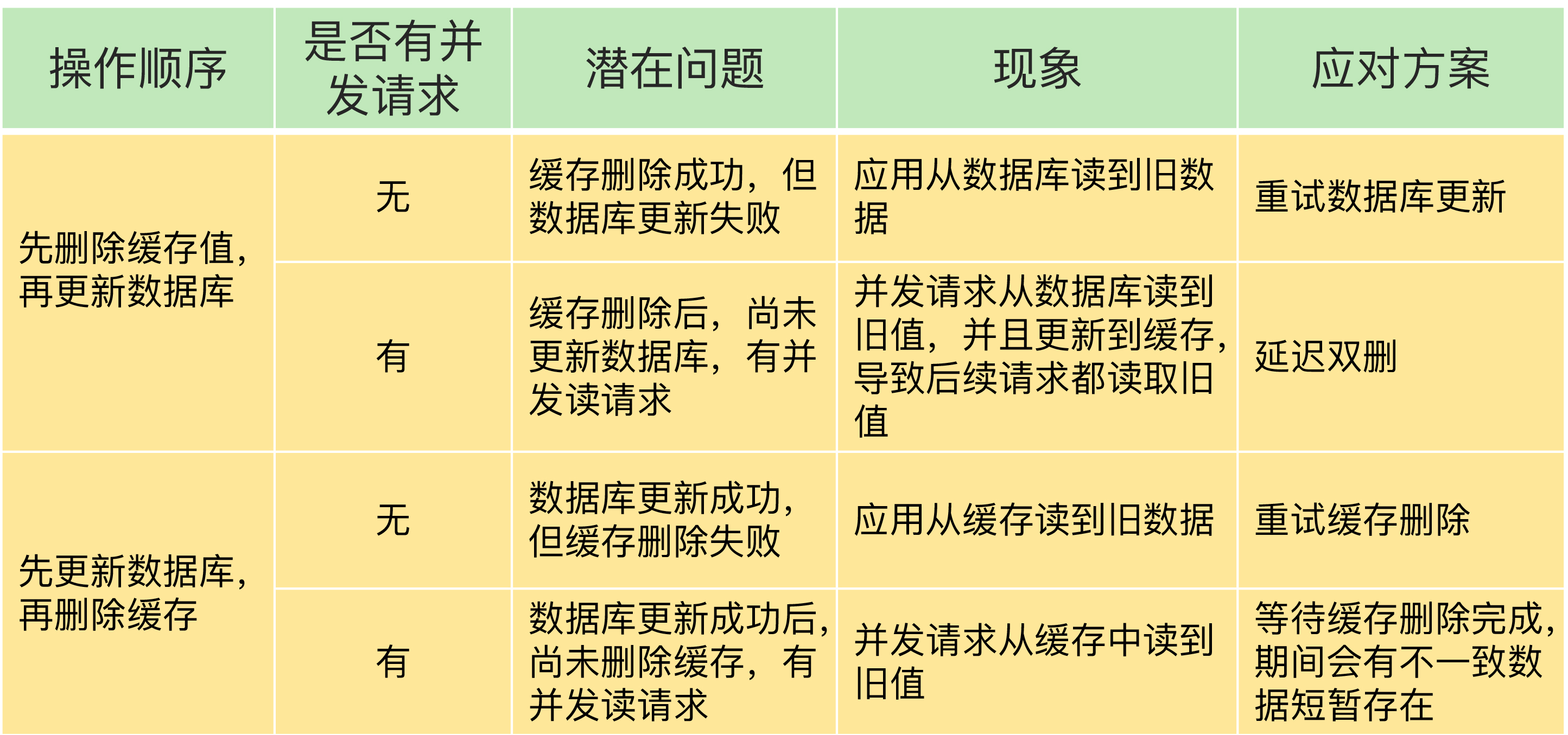
Redis 数据库双写不一致问题
缓存问题
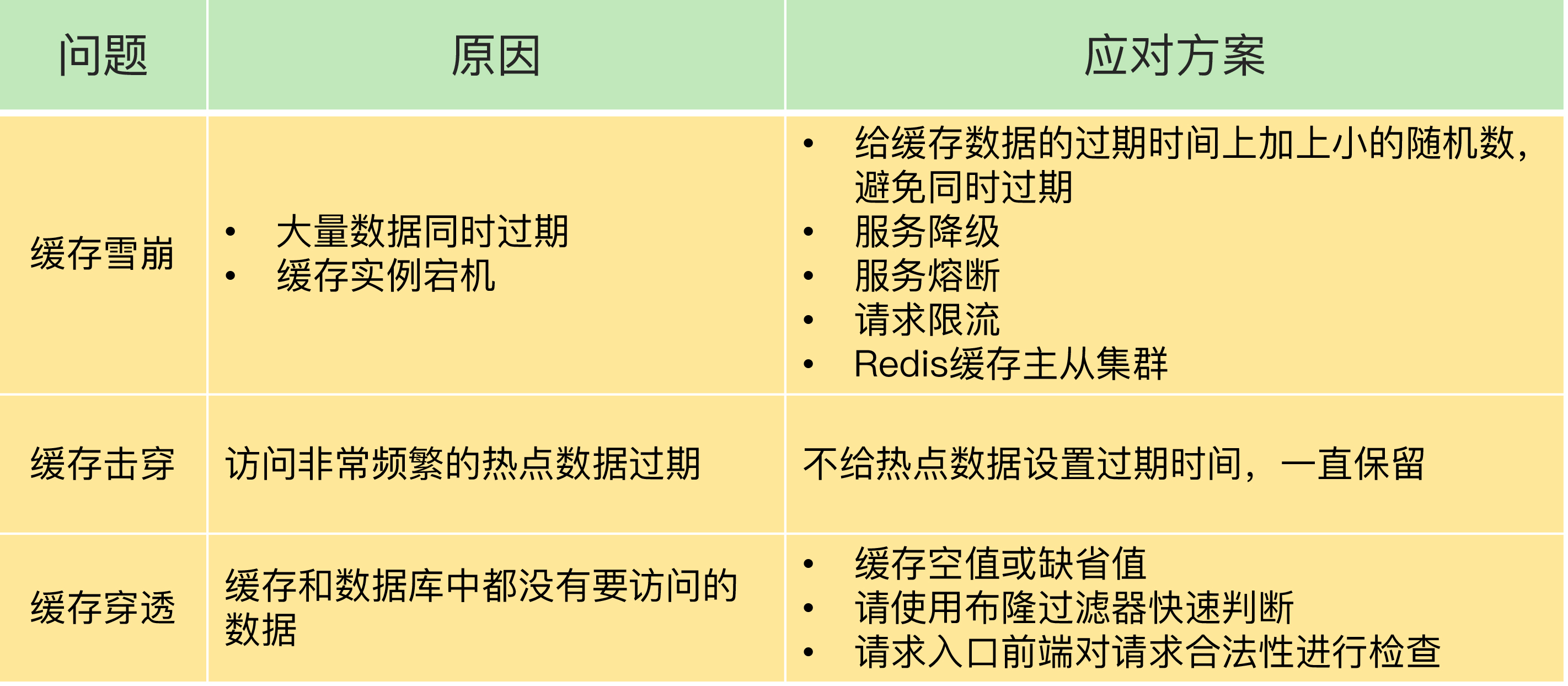
事物
MULTI/EXEC/DISCARD/WATCH
- 命令入队时就报错, 会放弃事务执行, 保证原子性
- 命令入队时正常, 执行时报错, 不保证原子性
- EXEC 执行时实例故障, 如果开启了 AOF,可以保证原子性
主从同步
读取过期数据
- 异步复制, 无法保证强一致性 | 保证良好网络环境, 使用监控程序监控从库复制进度, 一旦从库复制进度延迟超出阈值, 关闭从库与客户端的连接
- 使用 EXPIREAT/PEXPIREAT 设置过期时间点, 而不是相对时间 (考虑到同步延迟, NTP 同步)
practical experience
redis 变慢 checklist
- 使用复杂度过高命令或一次查询全量数据
- 操作 bigkey
- 大量 key 集中过期
- 内存达到 maxmemory
- 客户端使用短连接
- 当 redis 示例的数据量过大时, RDB 和 AOF 都会导致 fork 耗时严重
- AOF 的写回策略为 always, 次次刷盘
- Redis 实例运行机器的内存不足, 导致 swap
- 进程绑定 CPU 不合理
- Redis 开启了透明大页机制
- 网卡压力过大
慢查询日志 latency monitor
SLOWLOG GET 1
- slowlog-log-slower-than 微秒
- slow-max-len 最多纪录多少命令
排查 bigkey
redis-cli –bigkeys
cmd info
- server
- client
- stat
- keyspace
- commandstats
- cpu
- memory
- persistence
- replication
- cluster
- modules
使用建议
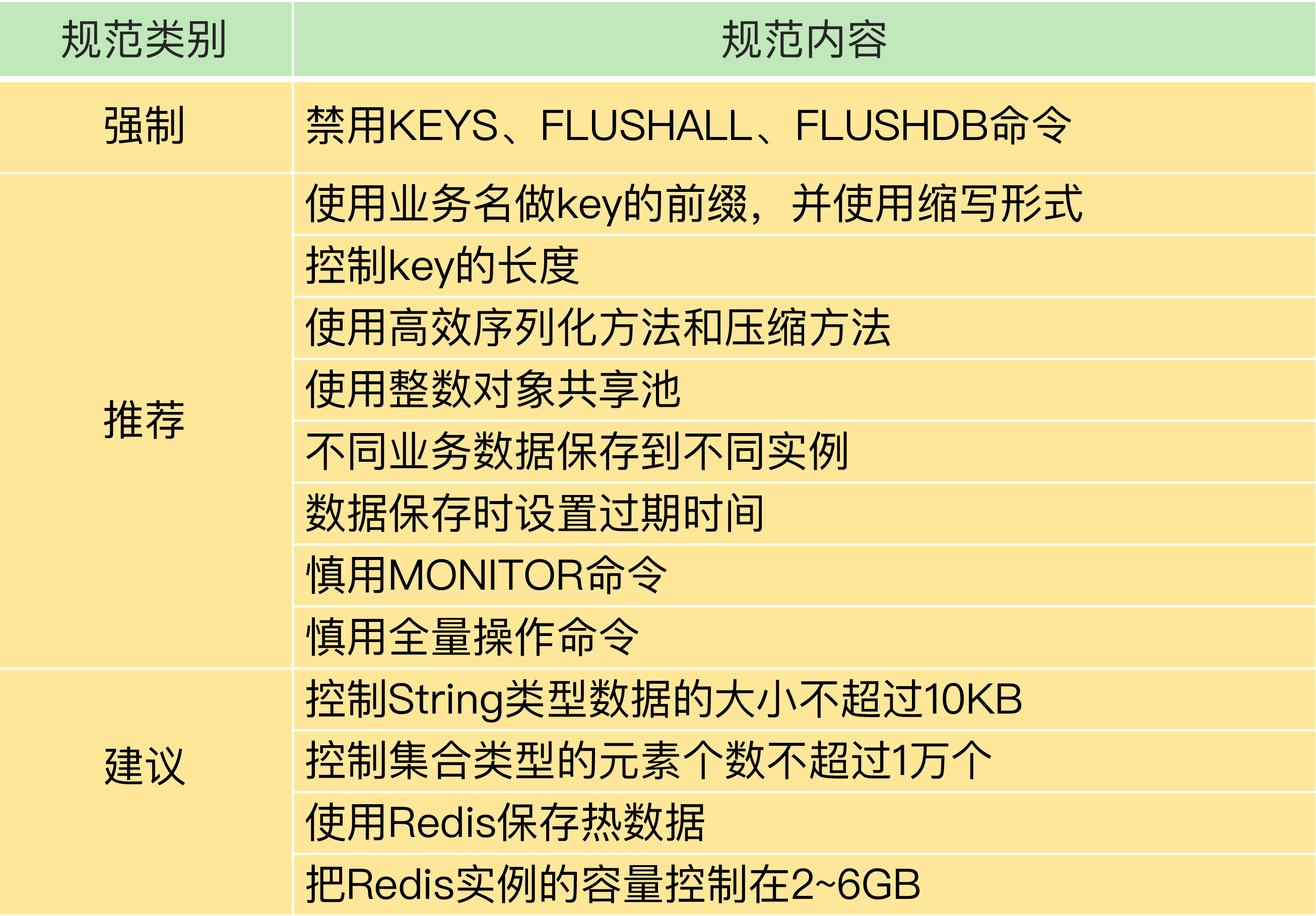
Redis 实战经验
- 针对持久化需求, 使用全量 RDB + 增量 AOF 策略
- AOF 日志刷盘时, 使用额外的 BIO 线程
- 增加了 aofnumber 配置, 控制日志文件的数量上限, 避免磁盘写满
- 定制化数据结构, 尽可能充分利用内存空间
- 结合 rocksdb (SSD), 实现冷热数据分离
- 使用 Redis 集群来服务不同的业务场景需求, 每个业务线拥有独立的资源, 互不干扰
- 客户端连接监听和端口自动增删
- Redis 协议解析: 确认路由, 拦截非法/不支持请求
- 路由转发
- 指标采集
- 平台平滑扩容/多租户支持/业务数据隔离/灵活的路由规则/丰富的监控功能
References
- Redis 核心技术实战 - 极客时间