心得
扎实的计算机基础
调优的对象不是单一的应用服务,而是错综复杂的系统。应用服务的性能可能与操作系统、网络、数据库等组件相关,所以需要储备计算机组成原理、操作系统、网络协议以及数据库等基础知识。具体的性能问题往往还与传输、计算、存储数据等相关,那还需要储备数据结构、算法以及数学等基础知识。
透过源码了解技术本质
深入源码,通过分析来学习、总结一项技术的实现原理和优缺点,这样我们就能更客观地去学习一项技术,还能透过源码来学习牛人的思维方式,收获更好的编码实现方式。
追问&总结
性能
- 响应时间
- 吞吐量
- 磁盘
- 网络
- CPU
- 网卡
- 防火墙
性能瓶颈
- CPU
- 内存
- 磁盘 I/O
- 网络
- 异常
- Java 所采用的异常堆栈处理模式
- 数据库
- 锁竞争
性能测试报告
- 接口的平均、最大和最小吞吐量
- 响应时间
- 服务器 CPU、内存、I/O、网络 I/O 使用率
- JVM GC 频率
调优策略
- 代码优化
- 设计优化
- 算法优化
- 时间换空间/空间换时间
- 参数调优
Java 程序性能优化
String.intern()- 正则表达式
- 少用贪婪模式,多用独占模式
- 减少分支选择
- 减少捕获嵌套
RPC
- 选择合适的通信协议
- 使用单一长连接
- 优化 Socket 通信
- 自定义报文
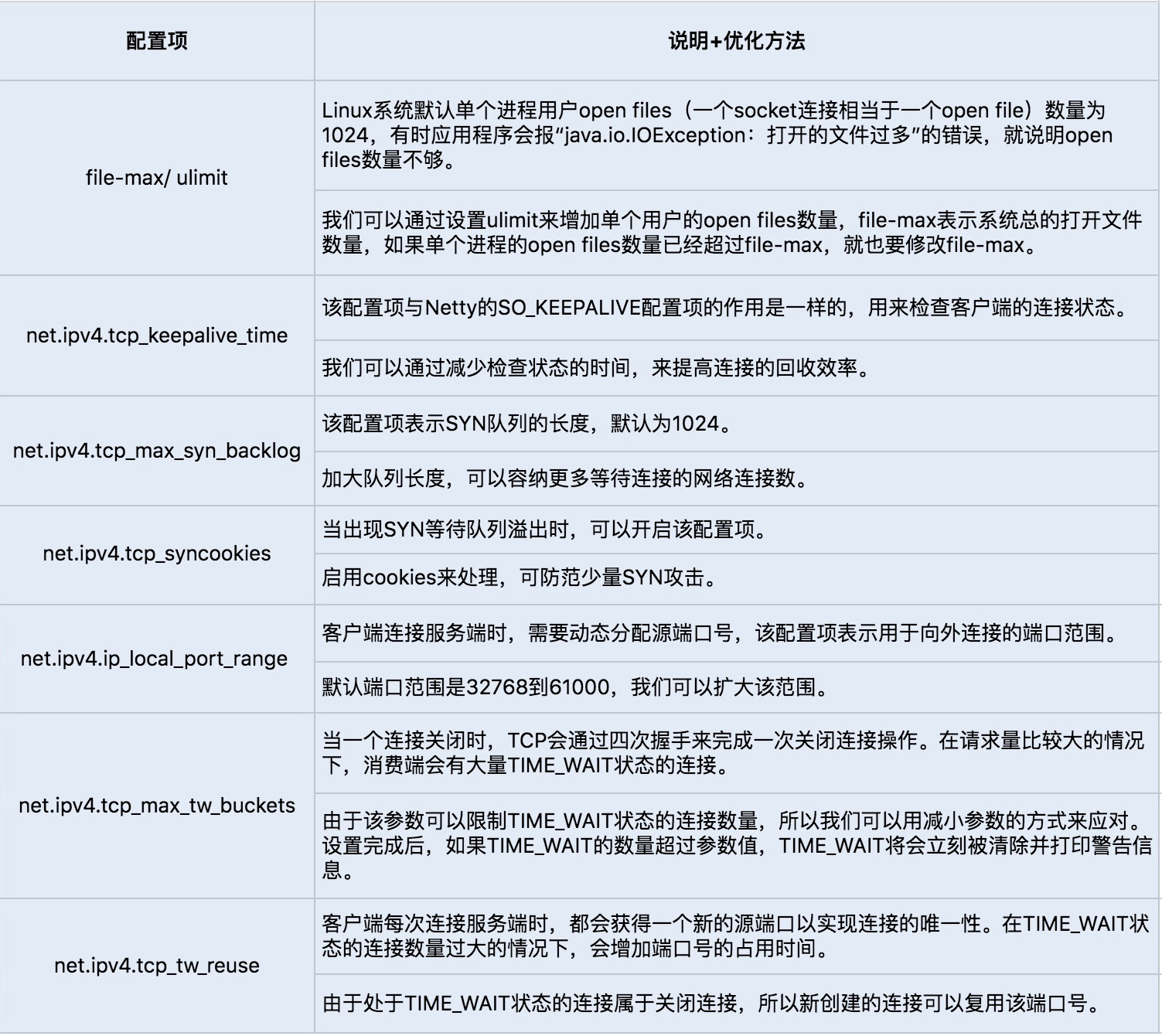
- 调整 Linux TCP 参数设置选项
多线程
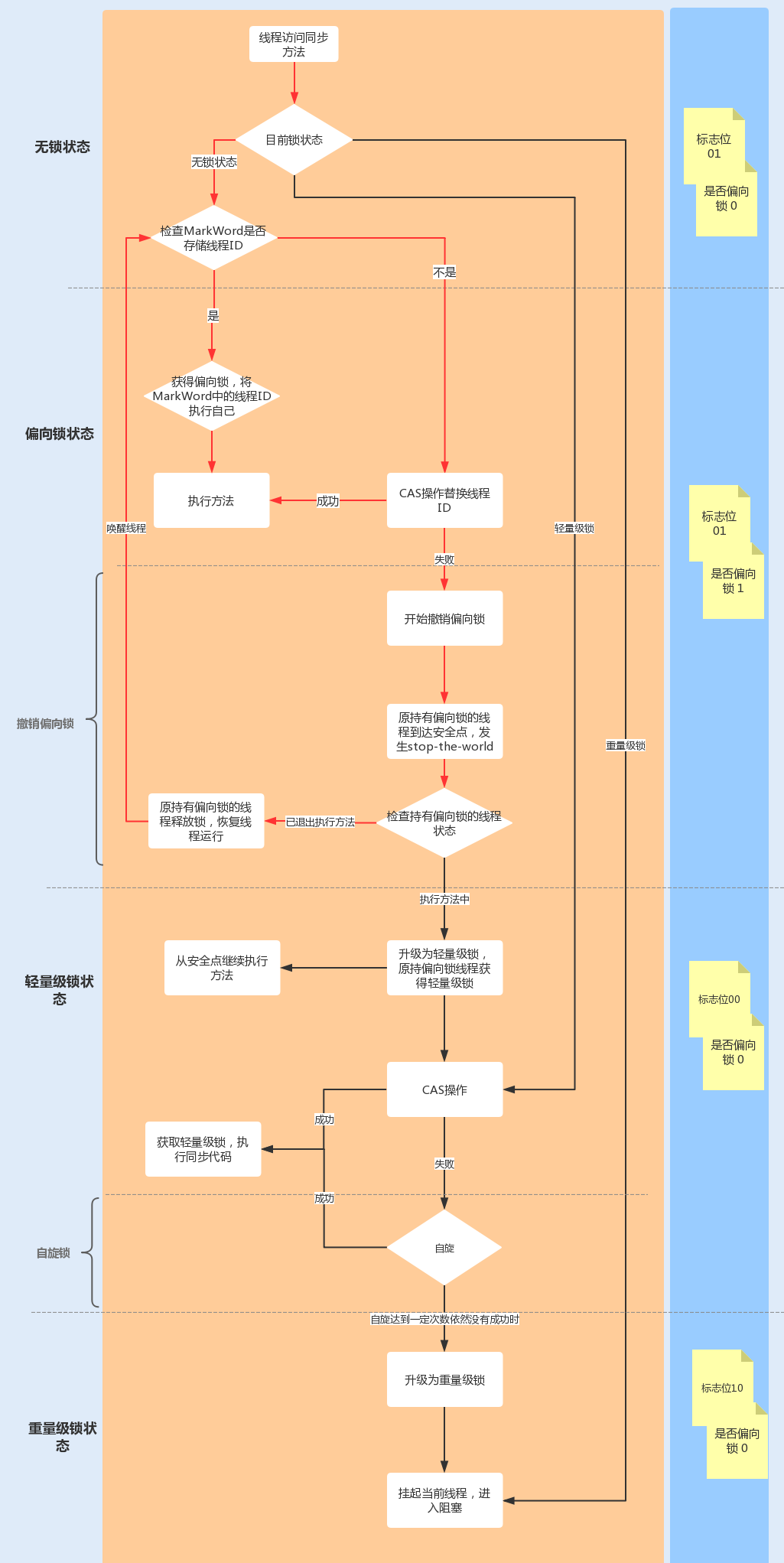
Lock / CLH
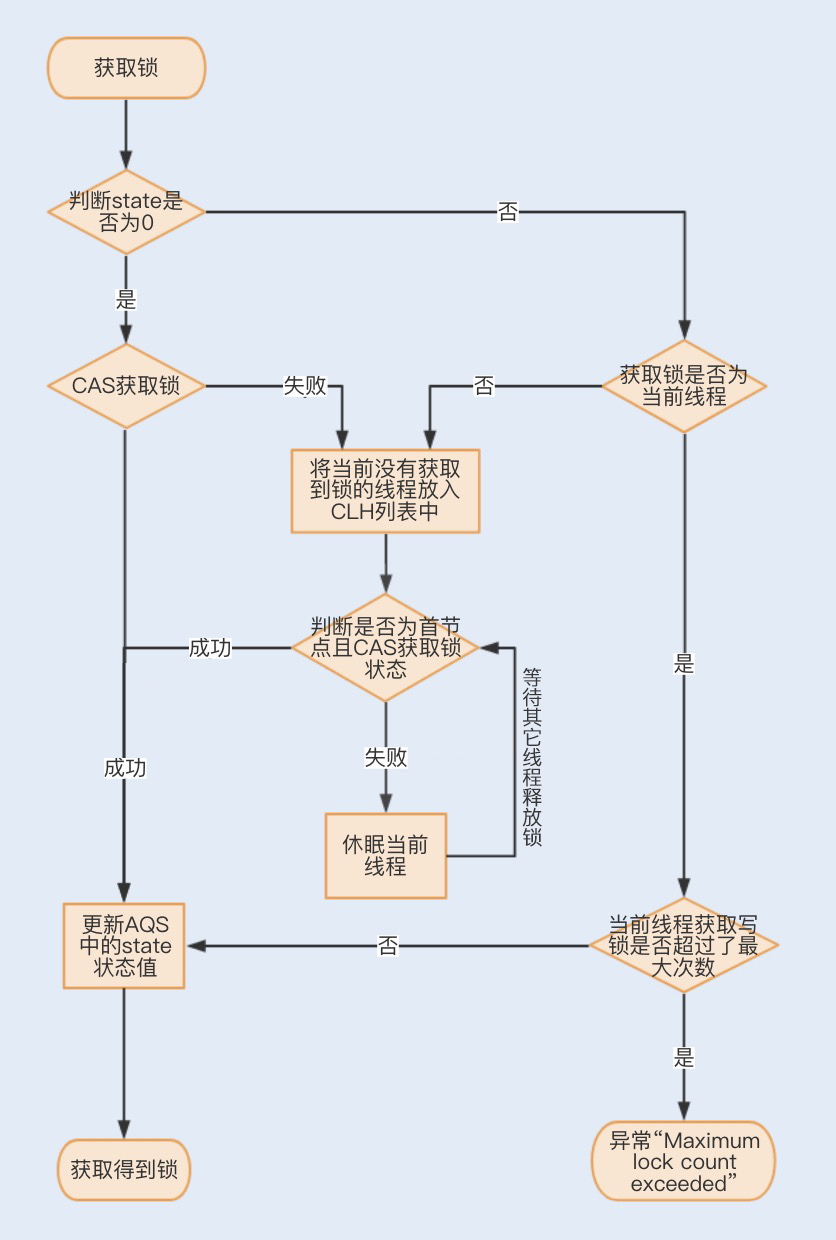
CAS
LongAdder 的原理就是降低操作共享变量的并发数,也就是将对单一共享变量的操作压力分散到多个变量值上,将竞争的每个写线程的 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的 value 值进行 CAS 操作,最后在读取值的时候会将原子操作的共享变量与各个分散在数组的 value 值相加,返回一个近似准确的数值。
Context Switch
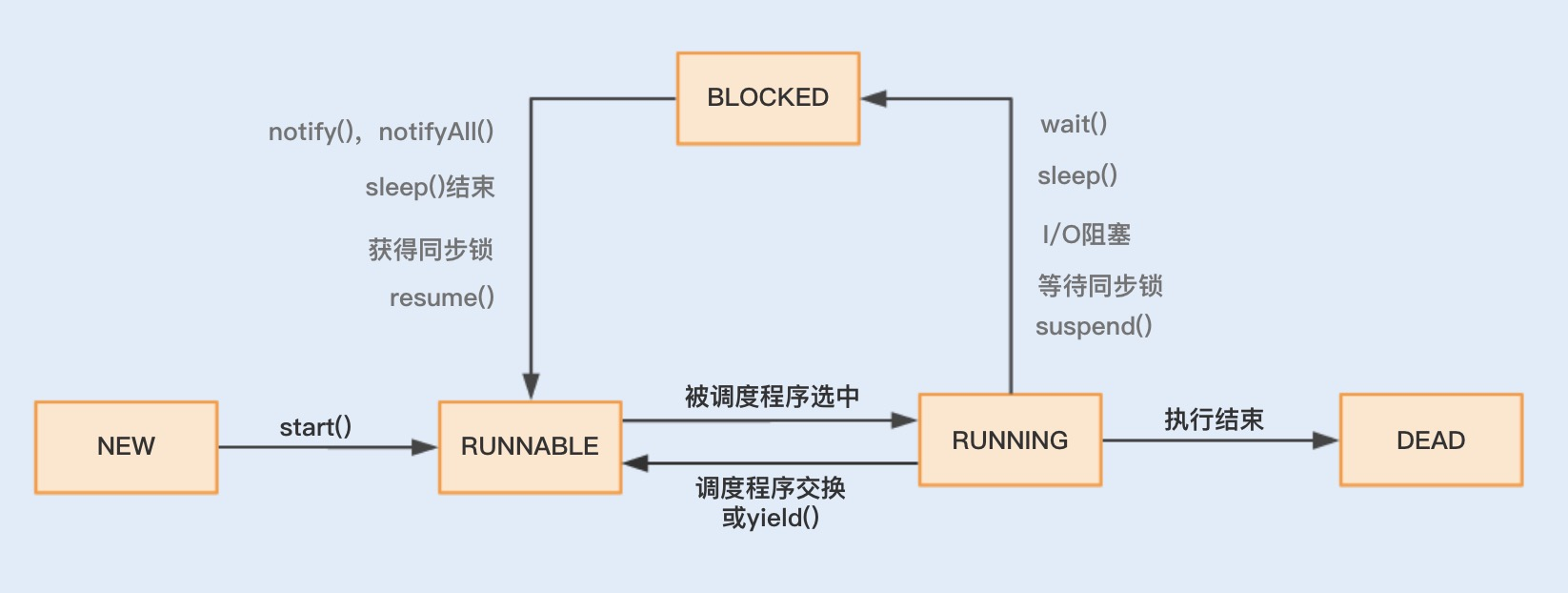
- 优化 wait/notify 使用,减少上下文切换
- 合理设置线程池大小,避免创建过多线程
- 使用协程实现非阻塞等待
- 减少 JVM 垃圾回收
JVM
JVM 启动流程
- JVM 向操作系统申请内存,JVM 第一步就是通过配置参数或者默认配置参数向操作系统申请内存,根据内存大小找到具体的内存分配表,然后把内存段的起始地址和终止地址分配给 JVM,后续进行内部分配。
- JVM 获得内存空间后,会根据配置参数分配堆、栈以及方法区的内存大小。
- class 文件加载、验证、准备以及解析,其中准备阶段会为类的静态变量分配内存,初始化为系统的初始值
- 初始化阶段,JVM 首先会执行构造器
<clinit>方法,编译器会在.java文件被编译成.class文件时,收集所有类的初始代码,包括静态变量赋值语句、静态代码块、静态方法,集合在一起组成<clinit>() - 执行方法,启动 main 线程,执行 main 方法,开始执行第一行代码。
JIT
编译后的字节码文件主要包括常量池和方法表集合。

- 方法内联
- 通过设置 JVM 参数来减小热点阈值或增加方法体阈值,以便更多的方法可以进行内联【占用内存会变高】
- 避免在一个方法中堆积太多代码,多使用小方法体
- 尽量使用 final, private, static 关键字修饰方法,编码方法会因为继承,需要额外的检查。
- 逃逸分析
- 栈上分配
- 锁消除
- 标量替换【若一个对象不会被外部访问、且可以被拆分,程序真正执行时可能就不会创建这个对象,而直接使用其成员变量】
设计模式
单例模式
|
|
上述实现单例的代码中,使用了 static 修饰成员变量 instance,所以该变量会在类初始化的过程中被收集进类构造器即 <clinit> 方法中。在多线程场景下,JVM 会保证只有一个线程能执行该类的 <clinit> 方法,其它线程将会被阻塞等待。
|
|
MySQL
sql 语句优化
- 无索引、索引失效导致慢查询
- 等待锁
- sql 语句不合适
select *- 在大数据表中使用 limit m, n 分页查询
- 对非索引字段进行排序
优化前步骤
- 通过 explain 分析 sql 执行计划
- select_type: simple, primary, union, subquery
- partitions
- type:
system > const > eq_ref > ref > range > index > ALL
- 通过 show profile 分析 sql 执行性能
如何优化
- 分页查询优化 - 子查询
- 优化
select count(*)- explain 获取近似值
- 额外缓存
- 优化
select *- 查询指定字段
|
|
- 覆盖索引优化查询
- 自增字段做主键 有序,可预测,范围
- 前缀索引优化
- 避免索引失效 对索引查询列进行额外操作
死锁问题
- 尽量按照固定的顺序来处理数据库记录
- 在允许幻读和不可重复读的情况下,尽量使用 RC 事务隔离级别,可避免 gap lock 导致的死锁
- 尽量使用主键更新
- 避免长事务
- 设置锁等待超时参数【innodb_lock_wait_timeout】
常用命令
vmstat
- r:等待运行的进程数;
- b:处于非中断睡眠状态的进程数;
- swpd:虚拟内存使用情况;
- free:空闲的内存;
- buff:用来作为缓冲的内存数;
- si:从磁盘交换到内存的交换页数量;
- so:从内存交换到磁盘的交换页数量;
- bi:发送到块设备的块数;
- bo:从块设备接收到的块数;
- in:每秒中断数;
- cs:每秒上下文切换次数;
- us:用户 CPU 使用时间;
- sy:内核 CPU 系统使用时间;
- id:空闲时间;
- wa:等待 I/O 时间;
- st:运行虚拟机窃取的时间。
pidstat
- u:默认的参数,显示各个进程的 CPU 使用情况;
- r:显示各个进程的内存使用情况;
- d:显示各个进程的 I/O 使用情况;
- w:显示每个进程的上下文切换情况;
- p:指定进程号;
- t:显示进程中线程的统计信息。
jstat
- class:显示 ClassLoad 的相关信息
- compiler:显示 JIT 编译的相关信息
- gc:显示和 gc 相关的堆信息
- gccapacity:显示各个代的容量以及使用情况
- gcmetacapacity:显示 Metaspace 的大小
- gcnew:显示新生代信息
- gcnewcapacity:显示新生代大小和使用情况
- gcold:显示老年代和永久代的信息
- gcoldcapacity :显示老年代的大小
- gcutil:显示垃圾收集信息
- gccause:显示垃圾回收的相关信息(通 -gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因
- printcompilation:输出 JIT 编译的方法信息