重点掌握
- 数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie
- 递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
复杂度分析
时间复杂度
- 只关注循环执行次数最多的一段代码
- 加法法则:总复杂度等于量级最大的那段代码的复杂度
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
常见时间复杂度
- 常量 O(1)
- 对数 O(
logn) - 线性 O(n)
- 线性对数 O(
nlogn) - 平方 O(n^2)
- 指数 O(2^n)
- 阶乘 O(n!)
空间复杂度
算法的存储空间与数据规模之间的增长关系。
|
|
分析手法
- 最好情况时间复杂度(best case time complexity)
- 最坏情况时间复杂度(worst case time complexity)
- 平均情况时间复杂度(average case time complexity)
- 均摊时间复杂度(amortized time complexity)
数据结构与算法
数组
为何数组坐标从 0 开始? 下标的更准确说法应该是: 偏移位数
|
|
BinarySearch
|
|
LinkedList
- 理解指针或引用的具体含义
- 警惕指针丢失和内存泄漏
- 利用哨兵减少实现难度【dummy head 节点】
- 重点留意边界处理
- 举例画图,辅助思考
- 多写多练
|
|
Edge Case
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
单链表反转
|
|
链表中环的检测
|
|
两个有序的链表合并
|
|
寻找中间节点
|
|
Stack
|
|
Queue
|
|
递归 Recursion
- 一个问题的解可以分解为几个子问题的解
- 这个问题与分解之后的子问题,除数据规模外,求解思路一致
- 存在递归终止条件
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
|
|
排序
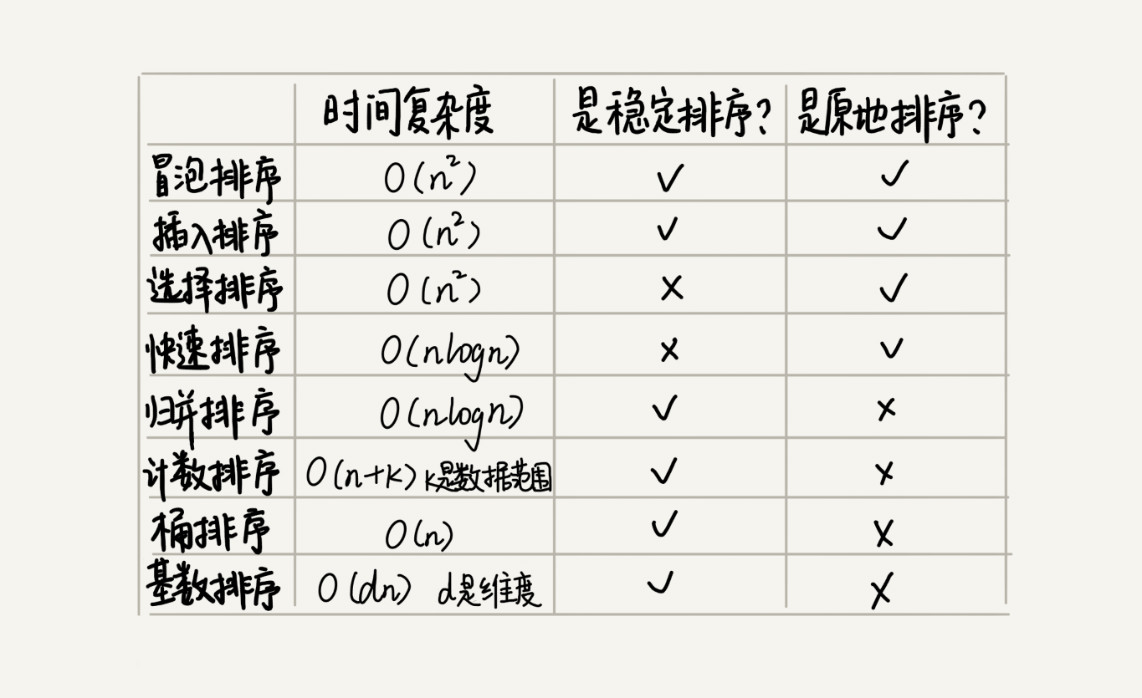
有序度是数组中具有有序关系的元素对的个数。满有序度: n*(n-1)/2,逆序度 = 满有序度 - 有序度。
- 最好情况、最坏情况、平均情况时间复杂度
- 时间复杂度的系数、常数 、低阶
- 比较次数和交换(或移动)次数
|
|
- bucket sort
- counting sort
- radix sort
桶排序的实践思路:假设经过扫描之后我们得到,订单金额最小是 1 元,最大是 10 万元。我们将所有订单根据金额划分到 100 个桶里,第一个桶我们存储金额在 1 元到 1000 元之内的订单,第二桶存储金额在 1001 元到 2000 元之内的订单,以此类推。每一个桶对应一个文件,并且按照金额范围的大小顺序编号命名(00,01,02…99)。
二分查找
|
|
变形问题
- 查找第一个等于给定值的元素
- 查找最后一个等于给定值的元素
- 查找第一个大于等于给定值的元素
- 查找最后一个小于等于给定值的元素
bisect_left在 = 的时候,无限左移 l = m -1bisect_right在 = 的时候,无限右移 r = l + 1
|
|
Skip List
插入时,为了维护索引与原始数据之间的平衡,引入一个随机函数,来决定将此节点插入到哪几级索引。
|
|
Hash
- 开放寻址法:Hash 冲突时,遍历寻找下一个空闲的位置,将数据填进去【删除数据时不能直接删除,需要采取特殊方式,如添加 DELETED 标志,防止开放寻址时无法找到数据】【适合数据量小,负载因子低的场景】
- 拉链法:Hash 冲突时,转化成链表【1 次 hash 后,再直接对比 key 值】
|
|
Hash 算法的应用
- 生成唯一标识
- 校验数据的完整性和正确性【分片下载】
- 安全加密
- 散列函数
- 负载均衡
- 数据分片
- 分布式存储
Tree
前序位置的代码只能从函数参数中获取父节点传递来的数据,而后序位置的代码不仅可以获取参数数据,还可以获取到子树通过函数返回值传递回来的数据。
一旦发现题目和子树有关,那大概率要给函数设置合理的定义和返回值,在后序位置写代码了。
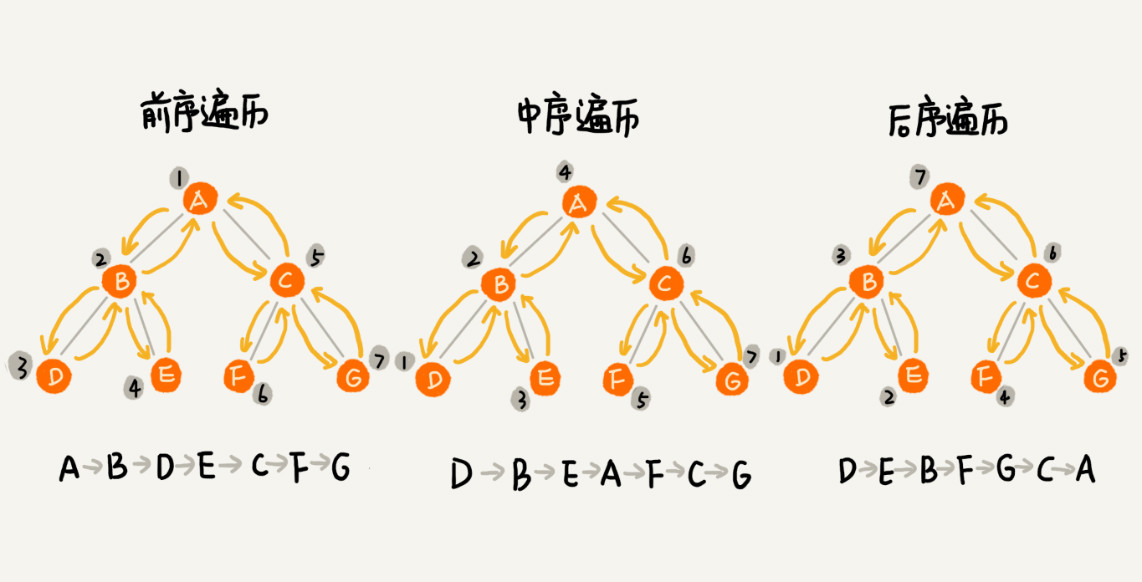
遍历
|
|
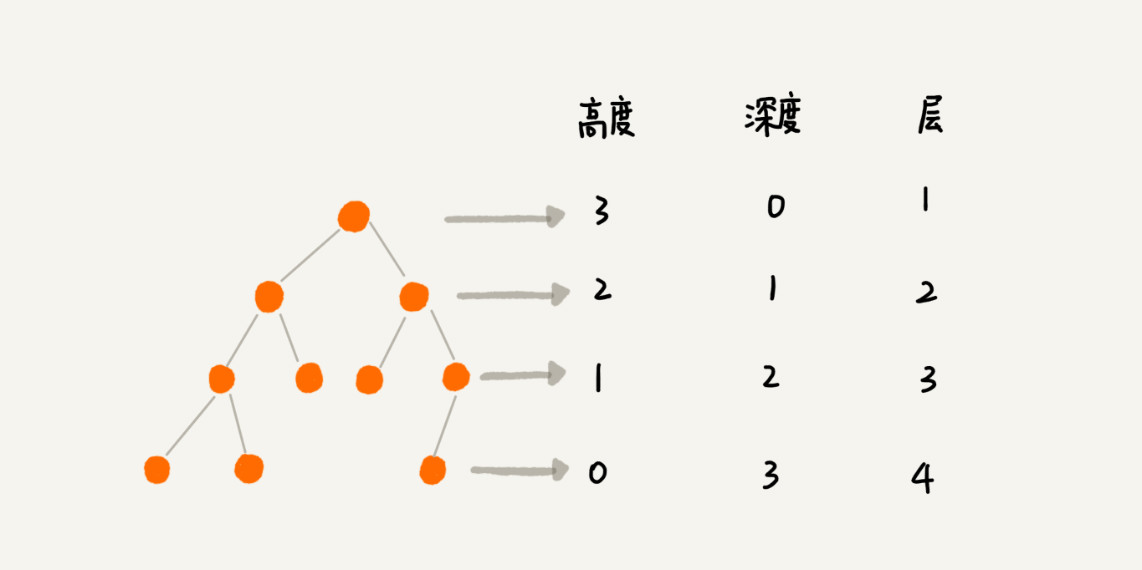
- 二叉树
- 满二叉树
- 完全二叉树【当用数组表示时,无需多余空间,可以填充满整个数组】【i,
2*ileft,2*iright】
遍历规则:
- 前序遍历: cur -> left -> right
- 中序遍历: left -> cur -> right
- 后续遍历: left -> right -> cur
红黑树
平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
字符串搜索算法
- BF 暴力查询
- RK 子串 hash,hash 匹配后再逐个判断
- BM BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(good suffix shift)。
- KMP 在模式串和主串匹配的过程中,当遇到坏字符后,对于已经比对过的好前缀,能否找到一种规律,将模式串一次性滑动很多位?
Trie
|
|
Greedy
- 分糖果
- 区间覆盖
概览
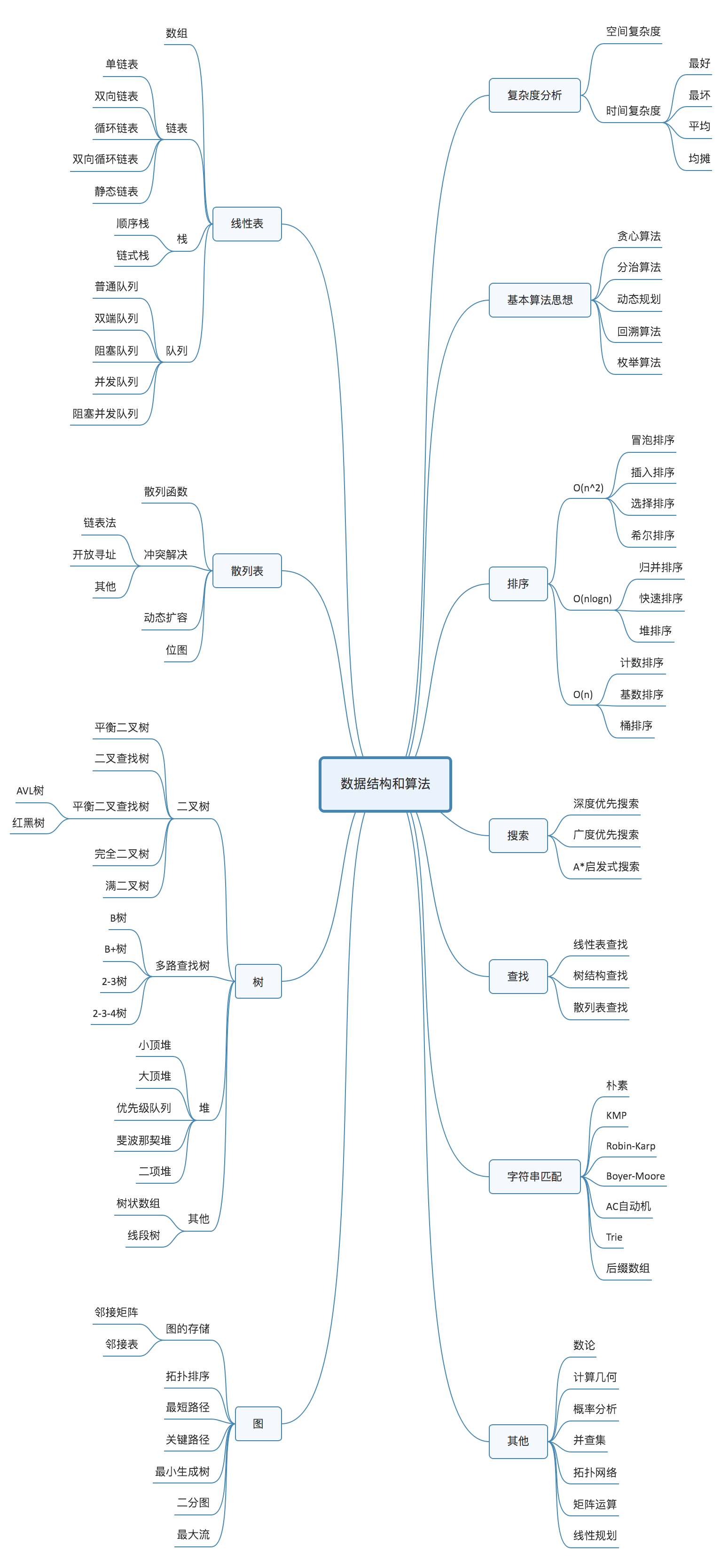
总结

Problems
对 D,a,F,B,c,A,z 这个字符串进行排序,要求将其中所有小写字母都排在大写字母的前面,但小写字母内部和大写字母内部不要求有序
用两个指针 a、b:a 指针从头开始往后遍历,遇到大写字母就停下,b 从后往前遍历,遇到小写字母就停下,交换 a、b 指针对应的元素;重复如上过程,直到 a、b 指针相交。
对于小写字母放前面,数字放中间,大写字母放后面,可以先将数据分为小写字母和非小写字母两大类,进行如上交换后再在非小写字母区间内分为数字和大写字母做同样处理
References
- 数据结构与算法之美 - 极客时间
- 《算法导论》